Replies: 35 comments 61 replies
-
aw_spawn_fork contains 2 things which are non-movable:
Since the child tasks begin executing immediately and capture a pointer to this control block (this happens during the call to fork()), its location must be pinned before they begin execution. There are several possible workarounds using detached tasks:
The need for these workarounds is a weakness of the current API that will be rectified in the future by #62 , which will enable std::future-like behaviors for tasks. Another option would be #75. As long as you don't use any blocking waits (tmc::post_waitable, std::future, std::mutex), all of the work will be executed eventually, even on a single core machine. |
Beta Was this translation helpful? Give feedback.
-
In my benchmarks the performance is similar. One major difference is that An additional reason to use |
Beta Was this translation helpful? Give feedback.
-
Threads don't suspend on locks in TMC. Only tasks. If you have an
|
Beta Was this translation helpful? Give feedback.
-
This is one of the core issues with stackless coroutines - that they introduce the "function coloring problem". If you want to call You could call |
Beta Was this translation helpful? Give feedback.
-
Yes... like you said, on some systems |
Beta Was this translation helpful? Give feedback.
-
|
OMG, thanks a lot for such detailed explanations! I'll keep the issue opened for a while in case I have more quesitons, ok? |
Beta Was this translation helpful? Give feedback.
-
It's not THAT bad in the engine I work on (this piece was not written by me) but still is a synchronous while-yield-blah waste of resources. I haven't found ANY DirectX API that would allow to do that asynchronously (post a request and get notified when the data is ready). Ideally we could suspend the rendering coroutine here and resume it once notified. What would be the best approach for this? I don't want to do sync-over-async crap. Something like, move such pieces to the main/legacy thread, suspend the rendering coro once it hits the point where we need to get the result, then wait for this loop in the main thread and post a coro resuming the rendering one?
Wouldn't this generate more code / yield worse optimization than a regular sync call to an inline which returns 2? (I use Clang 21 with
I suspect it would be more efficient to use the second approach? |
Beta Was this translation helpful? Give feedback.
-
If the API requires you to poll periodically, you will need to use a timer. Some coroutine libraries offer async timer facilities, but TMC does not offer them directly - rather you can use them via the Asio integration in tmc-asio. There are a couple examples of using the asio timer facilities here: https://github.com/tzcnt/tmc-examples/blob/main/examples/asio/timer_mem_bench.cpp However it's worth noting that there is no truly async timer. Under the hood, a thread is blocking on the OS timer syscall, and then posting the results back to the executor queue when ready. Your approach of doing this manually using the main thread is equivalent. I like the SwitchToThread() call - this may actually help performance in some cases as it's more lightweight than actually blocking on the timer. |
Beta Was this translation helpful? Give feedback.
-
Compilers are supposed to be able to inline coroutines, but often fail to do so at this time. The Clang 20 attributes (#61) are supposed to help with this. This particular item is near the top of my priority list... so it will be coming soon(tm). Notably you don't need to use inline tmc::task<int> fn() { co_return 2; }
tmc::task<void> fn2()
{
...
int x = co_await fn();
...
} |
Beta Was this translation helpful? Give feedback.
-
I'm not sure about this. It depends on the implementation of |
Beta Was this translation helpful? Give feedback.
-
In LLVM libc++, which I use, I'm a Linux dev, too, but this game is Windows-exclusive unfortunately :D (and porting its render from Dx 11.2 to Vulkan would be hell to me) |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
The advantage of the synchronous unlock are if the unlocking task is latency sensitive and you don't want it to suspend, or if you want to make use of the RAII lock scope object. |
Beta Was this translation helpful? Give feedback.
-
|
I'm going to convert this to a discussion; feel free to continue with any further questions there. |
Beta Was this translation helpful? Give feedback.
-
|
Not really related to TMC, rather to TMC-ASIO/ASIO... As for timers, you/we do: What is the best approach to run arbitrary functions on ASIO and then get the TMC completion token? The ASIO documentation is very cryptic and there are no good tutorials TBH.
I'm confused tho that
Why I need this (I think I mentioned it somewhere already): The whole game engine is planned to be run as coroutines on the So, my idea is: when I need to execute something outside of coroutines, I delegate it to ASIO and let it resume the calling coroutine upon completion. Of course, I could just create a standalone jthread and avoid using ASIO completely. But this would imply implementing an awaitable similar to Offtop P. S. Great news regarding atomics on Windows, as least when using LLVM's libc++: in LLVM 22, they finally implemented This API is not tied to scheduler slices, unlike |
Beta Was this translation helpful? Give feedback.
-
|
In general, you should only need to use functions in the For task/executor/awaitable manipulation, everything you need should be in the extern void DirectXBlockingCall(int Frame);
tmc::task<void> your_main() {
for(int frameNo = 0;;++frameNo) {
// prepare the new frame on ex_cpu
// The blocking call will occur on the Asio thread. ex_cpu threads will not be blocked.
co_await tmc::spawn_func(DirectXBlockingCall, frameNo).run_on(tmc::asio_executor());
}
}It's also worth noting that if you are going to call a blocking function, it doesn't really matter if you're calling it from a coroutine or a regular function - the issue is that the calling thread is blocked, and can't process any other work. So we just want to make sure that the thread that gets blocked is the Asio thread. Thus, the following 3 invocations are equivalent: co_await tmc::spawn_func(DirectXBlockingCall, frameNo).run_on(tmc::asio_executor());
co_await tmc::spawn_func([frameNo]() -> void {DirectXBlockingCall(frameNo);}).run_on(tmc::asio_executor());
co_await tmc::spawn([](int FrameNo) -> tmc::task<void> {DirectXBlockingCall(FrameNo); co_return;}(frameNo)).run_on(tmc::asio_executor());The only advantage of the first one is that it is quite a bit shorter, since I'm glad to hear that the implementation of |
Beta Was this translation helpful? Give feedback.
-
|
Usecase: in many places in the game engine, you need to update object state only once a frame, but then this state can be read concurrently from N threads when rendering. Async version of IOW (pseudo-code), The tricky part's that I see that currently most of such places is done like but with this approach, that each thread tries to take a lock even for a few nanosecs which means redundant contention/suspending/resuming. If we know in advance when to run an update and we're sure we'll fire it before any reader, then I think I can just use a manual reset event, but it's not a common case. UPD: Maybe something like |
Beta Was this translation helpful? Give feedback.
-
|
Using a regular mutex (async or not), you could still enhance this to reduce the likelihood of locking if you make if (curr_frame != obj.frame.load(std::memory_order_relaxed))
{
std::scoped_lock slock{lock};
if (curr_frame != obj.frame.load(std::memory_order_relaxed)) {
update();
obj.frame.store(curr_frame, std::memory_order_release);
}
}
read_without_locking();Further reduction in contention could be achieved by making Finally, you could dispatch individual tasks for each object, so that waiting for a lock would only impact that task, but not the rest. std::array<tmc::mutex, 64> objectLocks;
tmc::task<void> renderJob(Object& obj) {
if (curr_frame != obj.frame.load(std::memory_order_relaxed)) {
size_t hash = (reinterpret_cast<size_t>(&obj)) >> 4) % 64;
auto& lock = objectLocks[hash];
co_await lock;
if (curr_frame != obj.frame.load(std::memory_order_relaxed)) {
update();
obj.frame.store(curr_frame, std::memory_order_release);
}
// using co_unlock instead of scoped lock here to maximize mutex throughput
co_await lock.co_unlock();
}
read_and_process_without_locking();
}
tmc::task<void> renderer(std::vector<Object>& objects) {
co_await tmc::spawn_many(objects | std::ranges::views::transform(renderJob));
} |
Beta Was this translation helpful? Give feedback.
-
|
This lock is per-object already, right (stored inside the object class itself), sorry for confusion. Double-checking is a nice hint, thanks! One more thing, Did I get it right that if we unlock something at the end of a task, In this case, |
Beta Was this translation helpful? Give feedback.
-
|
If you are unlocking at the end of the task, This map emplace example is what I call a "shared output" - the tasks can process independently in parallel until they need to store their output in a single place. For this, you might find that you get better performance by separating the parallel and synchronous steps. Then you won't need a lock at all. std::unordered_map<std::string, std::string> map;
tmc::task<std::pair<Key, Val>> read_one(xml_node& node)
{
// some non-blocking code that takes most of task's time
co_return std::pair<Key,Val>(key,val);
}
std::vector<std::pair<Key, Val>> pairs = co_await tmc::spawn_many(xml | std::views::transform(read_one));
for (auto& p : pairs) {
map.emplace(p.first, p.second);
}This may have worse latency since you have to wait for all the subtasks to finish before you can start emplacing in the map. Or it may have better latency due to avoiding all the atomic overhead and cache line sharing. You should benchmark it. However, it's definitely more efficient in terms of system resource usage, so if there's any other tasks running in parallel with this, then it's a win. As you start to parallelize your system further, I recommend structuring your shared-output code like this when you can to maximize your overall bandwidth. IMO it's also easier to read and reason about. |
Beta Was this translation helpful? Give feedback.
-
|
Oh, now I understand the idea. Yeah, I think a lot of places in the engine could be rewritten that way. Your example also shows that the code could be more optimal sometimes if it was possible to customize the output of (unless I missed something and there's a helper in |
Beta Was this translation helpful? Give feedback.
-
|
All TMC awaitables pre-allocate fixed size space for results. Then each task receives a pointer into the results array to store its value. I couldn't do this with a map unless I knew the keys in advance. One thing that might be more efficient in minimizing overall latency would be #73 (comment) ... another TODO... |
Beta Was this translation helpful? Give feedback.
-
|
Not sure where to comment so I'll leave it here. According to this file: https://github.com/llvm/llvm-project/blob/main/libcxx/src/atomic.cpp Every OS has own restrictions on the size of an atomic object to implement efficient wait/notify API. Linux requires the object to be 4 bytes, Apple allows waiting on 4 and 8 bytes, while FreeBSD and Windows only implement efficient waiting on 8-byte objects (on x64). I'm mentioning this as IIRC you use the atomic wait/notify API in TMC. It's probably not a good idea to introduce platform/OS-specific macros/branches in the code, but unfortunately seems like there's no one-size-fits-all. |
Beta Was this translation helpful? Give feedback.
-
|
I see... I specifically switched to 4-byte because that's what Linux requires. Didn't realize the opposite is true on Windows. Thanks for bringing this to my attention. Fixed in #166 |
Beta Was this translation helpful? Give feedback.
-
Even before I started reworking the engine to TMC, I heard that it's not safe to use capturing lambda coroutines. auto second = co_await tmc::fork_clang(
[this, &SecondThreadTasksEndTime] [[nodiscard]] -> tmc::task<void> {
// ...
SecondThreadTasksEndTime = std::chrono::high_resolution_clock::now() - SecondThreadTasksStartTime;
}(),
tmc::current_executor(), xr::tmc_priority_any); // offtop: tmc_priority_any is shared between P-Cores and E-Cores
// some code that continues in parallel, including several co_awaits
co_await std::move(second);This expectedly crashes when trying to write to On the other hand, sometimes we can't do something without capturing. Let's say https://github.com/tzcnt/tmc-examples/blob/main/examples/alignment.cpp#L67 you use captures (by reference) and then call Maybe you could give a quick list of TMC "spawners" and say which ones can use lambda captures and which shouldn't? I have an assumption that if a coroutine is immediately awaited, like in the example above with
The second statement is due to that when you're creating a window, Windows records the thread ID which created it and then doesn't allow you to do anything with the window from any other thread. My current TMC settings: auto topo = tmc::topology::query();
auto& cpu = tmc::cpu_executor();
if (topo.is_hybrid())
{
tmc::topology::topology_filter p_cores, e_cores;
p_cores.set_cpu_kinds(tmc::topology::cpu_kind::PERFORMANCE);
e_cores.set_cpu_kinds(tmc::topology::cpu_kind::EFFICIENCY1);
// xr::tmc_priority_high{0};
// xr::tmc_priority_any{1};
// xr::tmc_priority_low{2};
cpu.add_partition(p_cores, xr::tmc_priority_high, xr::tmc_priority_any + 1).add_partition(e_cores, xr::tmc_priority_any, xr::tmc_priority_low + 1);
}
cpu.fill_thread_occupancy().init();I think it's the same as in your example: prio 0 is exclusive to P-Cores, prio 1 is shared, prio 2 is exclusive to E-Cores. (it's interesting tho why 8 E-Cores have 2 cache groups on my Alderlake) The rework is far from done, but is ongoing. The engine initialization is done (inc. concurrent parts), the main menu works. |
Beta Was this translation helpful? Give feedback.
-
|
Lambda captures are valid before the first The workaround for this is to always pass external references/pointers as parameters to the coroutine function. The pattern you observed in std::ranges::views::transform([&](size_t idx) -> tmc::task<void> {
return run_one(idx, &r1[idx], &r2[idx]);
});If I were to change // this will cause a use-after-free
std::ranges::views::transform([&](size_t idx) -> tmc::task<void> {
co_return co_await run_one(idx, &r1[idx], &r2[idx]);
});There is another example of this that makes it a bit more clear at https://github.com/tzcnt/tmc-examples/blob/fc45fc96576c35965ac90a6a7ae1bcc3d2adfe5f/tests/test_executors.ipp#L156 notice that there are two levels of lambdas, with the outer one taking the reference parameter and loop count, and passing them all on as parameters to the inner one. This pattern is really ugly so I usually prefer to use a named function on the inside. |
Beta Was this translation helpful? Give feedback.
-
|
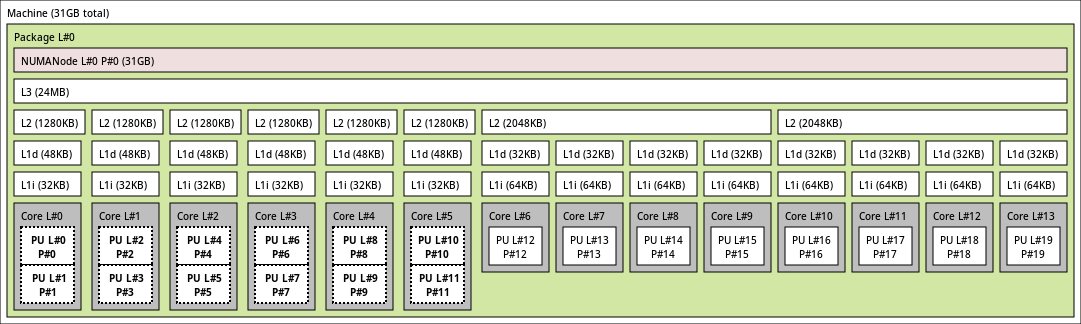
BTW I'm considering the creation of a Intel E-cores so far have come in clusters of 4 which share an L2. You can see the lstopo for an equivalent system here: https://www.open-mpi.org/projects/hwloc/lstopo/images/RaptorLake-hybrid.v2.10.png Theoretically this should mean that inter-core latency between E-cores that share an L2 is lower than to the other E-core group, or to the P-cores. I'm not sure whether this is actually true for Alder Lake generation, but I've been told recently that it's definitely true for Lunar Lake. Probably worth testing without using SMT on the P-cores, or without using full SMT ( I'm glad to hear that things are going well so far. I did try to design features with game engines in mind. If you run into anything that really doesn't work, I'd like to hear about it. I'd also love to try playing this version of the game at some point, if you'd be willing to give me some guidance about how to setup the necessary game / mod files. It would probably be better to communicate about that through a different medium (Discord?). |
{kind=link}
Beta Was this translation helpful? Give feedback.
-
Aaah, right, I didn't notice the outer wrapper, thanks! Also i noticed that the previously failing task above, after rewriting, works fine, despite that auto second = co_await tmc::fork_clang(
[this] [[nodiscard]] -> tmc::task<void> {
For now, I had like 2 places where I'm loosing the function coloring due to external callback crap. For example, WinAPI uses "wndproc" callbacks which you need to set to respond to window/OS events. I created a simple vector (since I know it can be changed from only one thread at a time) of delegates (which I mentioned some time ago) and from the callbacks where I don't have the coroutine context anymore, I just add a new item there. The vector is then processed once a frame (just before rendering) from the normal coroutine context. Nothing performance-critical there, so a tiny delay is fine. |
Beta Was this translation helpful? Give feedback.
-
|
Capturing anything is unsafe. The capture list of a coroutine lambda must be completely empty. The core guidelines recommend just using named functions instead https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#rcoro-capture . If you need to capture BTW there is another guideline in this section which you can ignore https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#rcoro-reference-parameters as it's not an issue if you wait for the coroutine to finish before the referenced object is destroyed (assuming it lives in the caller's scope) |
Beta Was this translation helpful? Give feedback.
-
|
Any good solution to preserve Imagine this: [[nodiscard]] bool key_press(gsl::index key);The compiler will warn if [[nodiscard]] tmc::task<bool> key_press(gsl::index key);The compiler still warns and that's good: a good protection and a reminder that it's a coroutine, so it should either be
|
Beta Was this translation helpful? Give feedback.
-
|
Difficult problem. I tried returning a wrapper object The only thing that worked was applying I'm not sure if there is a less broad solution. Perhaps a |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, Regarding |
Beta Was this translation helpful? Give feedback.
-
|
I've come around to this idea, mostly because there's no other way to accomplish this for primitive types - it has to be done inside the library. And I am a big fan of compile-time safety. You want to try out this branch and let me know if it works for you? https://github.com/tzcnt/TooManyCooks/tree/awaitable_result_nodiscard Also I'm open to ideas on shorter macro names... that one is a bit of a mouthful, but I want to clarify that it only affects the result (most of the awaitables themselves are already nodiscard). |
Beta Was this translation helpful? Give feedback.
-
|
I believe it's a good name. I've just tested it and it indeed works -- I've changed the return type of one local coroutine from Thanks a lot! |
Beta Was this translation helpful? Give feedback.
-
|
Merged into main. I shortened the macro to enable it to TMC_NODISCARD_AWAIT |
Beta Was this translation helpful? Give feedback.
-
|
Yet another question... I already refactored the main rendering function to be able to use Pseudo-code which could help understand this: tmc::task<void> CRender:render()
{
auto main = tmc::fork_clang(run_main());
const bool sun = // here we check if we need to render sun;
if (sun)
// here we need to fork sun_run();
... // render() continues here, draws the main scene etc.
if (sun)
// here we need to co_await sun_run()'s fork;
...
} |
Beta Was this translation helpful? Give feedback.
-
|
auto secondaryRenders = tmc::fork_group();
if (sun) { co_await secondaryRenders.fork_clang(sun_run()); }
if (rain) { co_await secondaryRenders.fork_clang(rain_run()); }
if (lights) { co_await secondaryRenders.fork_clang(lights_run()); }
// draw main scene
co_await std::move(secondaryRenders);If you need to return results from these, then you'll need to set the |
Beta Was this translation helpful? Give feedback.
-
|
Good idea. Unfortunately, I need to wait for the rain and sun in different places (rain needs to be rendered earlier than the sun, and the sun rendering is heavier, so we wait for it later than for the rain) =\ (https://github.com/solbjorn/reaper-engine/blob/tmc/ogsr_engine/Layers/xrRenderPC_R4/r4_R_render.cpp#L208, rain is awaited on line 208, sun is on line 265) Would I waste a lot of cycles if I fork them one by one, but the forked coroutine will actually do nothing besides checking that there's no rain/sun? |
Beta Was this translation helpful? Give feedback.
-
|
For a coro that doesn't create an allocation and isn't stolen by another thread the time taken is under 20ns. I wouldn't worry about it in general. Even if there was an allocation happening, since you're using mimalloc the total wastage would be less than 100ns. These are conservative numbers, I think the actual overhead is much lower. With that said, you can just use a separate |
Beta Was this translation helpful? Give feedback.
-
|
IOW this is allowed and will work as expected? Cool one, I didn't even know you can create a fork group and leave it empty if needed. auto sun_fg = tmc::fork_group();
if (sun) { co_await sun_fg.fork_clang(sun_run()); }
auto rain_fg = tmc::fork_group();
if (rain) { co_await rain_fg.fork_clang(rain_run()); }
auto lights_fg = tmc::fork_group();
if (lights) { co_await lights_fg.fork_clang(lights_run()); }
// main scene
co_await std::move(rain_fg);
// ...
co_await std::move(sun_fg);
// ...
co_await std::move(lights_fg); |
Beta Was this translation helpful? Give feedback.
-
|
All of the awaitable grouping functions (spawn_tuple, spawn_many, spawn_group, fork_group) work when empty. Even when setting the Count template parameter, Count is only the maximum, but you can pass less if needed (by also passing a count or iterator end runtime parameter) |
Beta Was this translation helpful? Give feedback.
-
|
Might be helpful: Too pity it didn't make it to LLVM 22. |
Beta Was this translation helpful? Give feedback.
-
|
Check the discussion on the PR - unfortunately it's not sufficient for real world use cases yet. But it's a step in the right direction. |
Beta Was this translation helpful? Give feedback.
-
|
Ooops, I didn't read the comments -- you were already aware of this. I hope they'll continue working on it. |
Beta Was this translation helpful? Give feedback.
-
|
Breh, I completely forgot about the utility awaitables and was wrapping oneliners in lambdas... When I need to execute something on the standalone co_await tmc::spawn([](auto& last) -> tmc::task<void> {
PIX_EVENT(DEFER_FLUSH_OCCLUSION);
for (auto light : last)
{
if (light == nullptr)
continue;
for (auto& svis : light->svis)
svis.flushoccq();
}
last.clear();
co_return;
}(Lights_LastFrame)).run_on(xr::tmc_cpu_st_executor());Now I'm thinking of just {
auto scope = co_await tmc::enter(xr::tmc_cpu_st_executor());
PIX_EVENT(DEFER_FLUSH_OCCLUSION);
for (auto light : Lights_LastFrame)
{
if (light == nullptr)
continue;
for (auto& svis : light->svis)
svis.flushoccq();
}
Lights_LastFrame.clear();
co_await scope.exit();
}The second should be more optimal I guess? IIRC P. S. In case you haven't seen my comment in #175:
:3 It's funny nonetheless that TMC is 3x faster than TF even without Chase-Lev queues :D |
Beta Was this translation helpful? Give feedback.
-
No PRNG (Pseudo RNG) is "cryptografically secure", so it's only a matter of performance and distribution. The second can have huge impact on results. I've noticed you played a bit with snmalloc -- any interesting results comparing to tcmalloc? From their docs and articles, I got an impression that it performs better on clusters and 60+ thread Xeons rather than on consumer CPUs... But I could've misinterpreted it. I'm limited to mimalloc as of now (but there's nothing bad in it, especially after the 3.2.7 release), as only this lib can work as a proxy for the entire process space -- sorta poor man's |
Beta Was this translation helpful? Give feedback.
-
|
Snmalloc was close to tcmalloc but still slightly slower on my 64 core machine. The design seems theoretically good so it's one to keep an eye on. It seems that tcmalloc at least has the patch functionality to override the global allocator even for other DLLs, although I didn't find clear documentation on how to do so. I suppose if you are able to achieve your goal of a fully statically linked exe then you could experiment with any allocator you like. |
Beta Was this translation helpful? Give feedback.
-
tcmalloc from gperftools yes, but I believe you use the new tcmalloc which Google develops for Linux exclusively? I currently have fully statically linked exe (now that I got rid of oneTBB), but with injection/redirection you also have 3rd party allocator taking care of any allocation that happens inside the process space. Let's say you can't link in Windows DLLs or DirectX DLLs or any proprietary DLLs which don't have source code statically. When you use mimalloc-redirect or any other similar hacks, you also have allocations from these DLLs managed by your allocator. If you link the allocator statically, you only have allocations that come from your binary managed by the allocator. I'm fine with mimalloc anyway, Tracy didn't find any allocator-related bottlenecks. I've also found some completely new allocator which also injects entry points similarly to mimalloc-redirect, but it's on early WIP stage currently. I might play with it later when it's more mature. |
Beta Was this translation helpful? Give feedback.
-
|
I use the Debian and Arch packages which are based on the old gperfools version. Since installing them is dead simple I felt it was fair to recommend their usage with the library. |
Beta Was this translation helpful? Give feedback.
-
|
Hmmm, you should definitely give this a try: https://github.com/google/tcmalloc It is Linux-exclusive, so I can't test it with the engine, but IIUC this is a "new generation" of TCMalloc. Also since you have slightly better results with the "classic" version than with mimalloc, maybe I'll also try the one from gperftools soon... It supports Windows and have DLL patching as you mentioned, although building it for Windows is a separate painful story. |
Beta Was this translation helpful? Give feedback.
-
|
I've found at least one such pattern in the code: m_playing_sounds.erase(std::remove_if(m_playing_sounds.begin(), m_playing_sounds.end(), CInappropriateSoundPredicate(sound_mask)), m_playing_sounds.end());where I need to change the For now it looks like I need to convert this to a manual loop in order to do that, there is no other way? |
Beta Was this translation helpful? Give feedback.
-
|
The reason why I'm converting a lot of functions to coroutines now is that xrSound loads next blocks of oggs asynchronously: when its state machine decides that we'll need the next block soon, it tosses a task to the executor. In order to correctly stop or destroy the sound, I need to make sure its task is done. That's how stop/destroy became coroutines (they BTW for such async tasks (which don't fit the fork-join model) I use |
Beta Was this translation helpful? Give feedback.
-
|
If you only need to await the task in one place, then I'd say use a (I should clarify the doc comment on fork_group to say it's fine to call However if you might need multiple other tasks to wait for one event, then you should continue to use |
Beta Was this translation helpful? Give feedback.
-
|
As for the example above (details calculation), then there's only one awaiter (details render task, by "details" the original devs meant grass). Sounds can be awaited from multiple places, so yes, there can be multiple |
Beta Was this translation helpful? Give feedback.
-
|
Calling Actually I think the documentation does clearly state this: https://fleetcode.com/oss/tmc/docs/v1.3/awaitables/fork_group.html#_CPPv4N3tmc13aw_fork_group5resetEv . Should I also note that it's reusable in this manner at the top level of the docs? Since this resettable behavior is special to spawn_group and fork_group, I can see how it could get lost if it's buried on the function doc only. |
Beta Was this translation helpful? Give feedback.
-
|
I think it's just me not reading the docs deeply =\ So if I got it correctly,
It should behave similarly to detach + reset event, but more optimized. I've just recalled that the details rendering function is called from several places, so it might not be a good candidate. But I have a couple others that for sure are (async rain calculation, async HOM calculation — each is awaited exactly once; maybe something else will come to my mind later). Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
Re "why I convert so many functions to coroutines" (note to myself mostly). For sure, I could just leave everything as it is, just use Lots of folks kept telling me that it's impossible to replace Luabind with Sol in the engine. It took me half a year and several thousand locs, but I made it. So I'm pretty sure this challenge is doable as well, especially given that I receive so huge and helpful support from you. (the same folks told me it's not possible to switch the engine from MSVC to Clang/clang-cl due to the legacy code that is too broken to be fixed -- lol that was EZ honestly, even though I wasn't good in C++ back then) BTW I'm curious how Tracy will work after the engine is coroutine-based -- I haven't read its code deeply, but my impression was that Tracy expects every function to start and end on the same thread and doesn't expect that a function can suspend. |
Beta Was this translation helpful? Give feedback.
-
|
Yes, I think it is an admirable goal to make the entire thing non-blocking and should be achievable. I'm happy to help and appreciate your useful feedback on the library. I just meant that only the outermost (awaiting) and innermost (first level that needs to be parallel or async) actually need to be coroutines. You can make everything in between a regular function if that simplifies development. The innermost regular function can construct or fork the coroutines without needing to await them, and then provide the awaitable back to the outermost coroutine which awaits it later. This can be done in a few ways:
Re: the sound example - after you get this working with the "queued to main thread" approach, a next step might be to decouple sound timing from the main thread entirely. If sound controls still need to be serialized, this might be a good place to use |
Beta Was this translation helpful? Give feedback.
-
|
Re: Tracy I found this which sounds like a problem wolfpld/tracy#936 . Not 100% sure I understand but the suggestion appears to be to track the current coroutine in the worker thread, before every resume call. Not sure how I can support that. I found this which is very cool https://github.com/tokio-rs/console but it implies that they built the entire thing from the ground up for Tokio. So we probably need a new tracing framework that is coroutine-aware for C++. Slightly related: debugging coroutine stacks is not well supported at the moment. I found this script https://clang.llvm.org/docs/DebuggingCoroutines.html#async-stack-traces but since the addition of llvm/llvm-project#166664 / llvm/llvm-project#161870 it seems that we should be able to provide a script to generate a nicer looking frame, which could perhaps be visible in a debugger GUI (I use LLDB DAP VSCode extension). Not sure. This is a bit of a rabbit hole but I'll probably take a stab at it at some point. It would be another "killer feature" for this project to be able to provide a fully working debugger integration. |
Beta Was this translation helpful? Give feedback.
-
Uff pity. I've read about their macros related to fibers, but I'd say they're poorly applicable to coroutines. Tracy zones are scope-based, it's a structure on the frame which has a constructor and a destructor which take care of the tracing info. But coroutines don't break the object scopes, otherwise it would be a hell, if (a)
{
scope_based_obj b;
co_await do_smth_async();
do_smth_sync(b);
}
// b gets destroyed only once and only when exiting the scope, the co_await doesn't affect its lifetime anyhowso I don't really understand how Tracy gets multiple exits from the same zone when using coroutines.
Correct, or at least that the devs of the already existing and popular frameworks like Tracy would start treating coroutines seriously and supporting it.
I had a couple crashes inside coroutines and got the following: the stack trace that gets printed to the log (generated by dbghelp.dll) showed me something like: TMC executor internals -> the call chain since the last suspension point. Same with minidumps generated by the same DLL. So the debug info is indeed poorer, but on the other hand, when I ran the exe under the VS debugger, all breakpoints and step-by-step execution worked as expected, so when a bug can be reproduced stably, it's not a problem to me. (might be related / help you: https://developers.facebook.com/blog/post/2021/10/14/async-stack-traces-c-plus-plus-coroutines-folly-walking-async-stack/) |
Beta Was this translation helpful? Give feedback.
-
|
FYI since I've been recommending the use of fork_group: #186 |
Beta Was this translation helpful? Give feedback.
-
|
I provided some info to the Tracy authors: wolfpld/tracy#936 (comment) |
Beta Was this translation helpful? Give feedback.
-
|
Just curious: tmc::post(
tmc::cpu_executor(),
tmc::detail::client_main_awaiter(
static_cast<tmc::task<int>&&>(ClientMainTask), &exitCode
),
0, 0
);Why is the root coroutine run with thread hint == 0 in |
Beta Was this translation helpful? Give feedback.
-
|
Since concurrentqueue creates an implicit producer queue for each unknown thread that posts, posting from the main thread creates one of these queues. If the app runs entirely on executors after that, that queue would remain empty but still need to be checked every iteration. By using the thread hint, it goes to the group 0 inbox which is an already-existing queue instead. Since the new waking algorithm prefers to wake thread 0 when there are no working threads anyway, this isn't a functional change. And there is a check that the hinted thread is actually allowed to execute the chosen priority; if it can't, the work item goes into the normal submission path (via the implicit producer queue) |
Beta Was this translation helpful? Give feedback.
-
|
The other quirk of the async_main implementation is that it uses std::atomic::wait instead of a future. It would be cleaner if I just included tmc/sync.hpp and called post_waitable. But I wanted to avoid introducing a dependency on <future> for users that never want to actually use it. So I tried to keep that constrained to the sync.hpp file. Edit: the above doesn't make sense any more since async_main is defined in ex_cpu.ipp which already includes sync.hpp. So I think I could make this change now. Posting from my phone, sorry Someone also suggested having the main thread become a worker thread. I could do this too and it would eliminate that issue, but comes with its own complexity. |
Beta Was this translation helpful? Give feedback.
-
|
Ah I see. I did the same (thread hint) in the engine, since I needed to open-code (https://github.com/solbjorn/reaper-engine/blob/tmc/ogsr_engine/xr_3da/x_ray.cpp#L401) I wouldn't change atomic wait/notify to a As for making the main thread a worker thread, it could be me as well. But I remember you explained this would require inverting some logic upside down and wouldn't give any reasonable benefits. Apart from the logic details, I think you have less control from the code over the "main" thread than over the threads you create manually? This could also complicate things. |
Beta Was this translation helpful? Give feedback.
-
|
Since it looks like you've finished the initial pass of the migration, I'd love to try playing the game. I was able to get your branch to build in Release, but no luck in Debug. However I'm not able to run it - the splash screen only pops up for a second and then disappears. When running in the debugger I see it's unable to find fsgame.ltx. However it doesn't emit any logs so I'm not sure what the next step is. I tried moving the files around and passing -fsgame parameter but no luck. I'm using the Steam 1.006 (?) version and was able to run the upstream OSGR engine just fine using the -steam parameter. Would you be willing to take some time to help me debug this? I joined the OGSR Engine and Open XRay discords so you can contact me there. If not I would appreciate some tips on getting it to find the fsgame / generate meaningful logs. Also is there a specific mod / graphical overhaul that I should be using? |
Beta Was this translation helpful? Give feedback.
-
|
Hi, it was the initial pass and I'm glad it's done, but there are still lots of mutexes etc. which I need to convert, otherwise there'll most likely be deadlocks (the current tmc branch of my repo has a weird crash when loading the level). I tried to build the Debug config in the past, but it was broken long before I forked the project and I didn't try to fix it properly (a Release build + game logs and sometimes the VS debugger have always been more than enough for me). My fork is not compatible with the original assets in a couple places: all.spawn file, XMLs with translations, etc, but the most problematic is Luabind -> Sol transition (lots of Lua scripts rewritten). The easiest way would be to give you my mod which is already adjusted, but unfortunately it has only Russian localization (most of scenario etc. expansions which I took as a base had only it). That's why I didn't reply when you previously asked for this -- just didn't have an idea how to solve this =\ If you have a good automated way how to translate several Mbs of dialogs/texts with a decent quality (AI or so, I'm fluent in English, but a manual translation would take me like a month maybe, really tons of text), then the idea is that here: https://github.com/solbjorn/reaper-build/tree/master/config/text you have XMLs with translations. Each string has a node for a specific language ("rus", "eng" etc.). So you basically need to take the value from "rus", translate it and add a second node "eng" with the translated text. After this is done, you'll also need several additional big files (with textures etc.) which I don't upload to the GH repo, and probably a couple adjustments in the main config, but it's not a big deal. I had a small "fixup" archive in the past which you could just drop to the S.T. installation and the vanilla game would work with my fork; but after I converted the engine from Luabind to Sol, it doesn't work anymore and I didn't update it since it would be too much work (and I can't just use the scripts from the mod since they are changed and improved heavily and rely in other features from the mod). What do you think? |
Beta Was this translation helpful? Give feedback.
-
|
I can AI translate the XMLs, should be good enough to make it playable. And if you are able to point me at where the other files are hosted and where to put them, then that should be all I need? After you get the crashes fixed, of course. Just curious, are you planning on doing a public release of this at some point? |
Beta Was this translation helpful? Give feedback.
-
|
(BTW I'm not from Russia if that matters :D) I didn't have any plans on public releases, just doing it for myself and having fun. The mod is also in ever-WIP state, the first map is playtested, but I don't promise there won't be script crashes / glitches etc. I got back to S.T. modding in 2023 after a long break (I was active in modding in 2008-2011, then in 2017-2018) and at first, I only wanted to play some old mod I felt nostalgic to, but then I started improving feature X, then Y, then... Step by step, deeper and deeper, and now my fork differs from OGSR by a couple times a thousand locs :D (we had no engine source code back in 2008 and had to work around engine bugs in the scripts as good as we could and often resign from something that couldn't be done on the original exe, now that the source code is open and there are several public projects like OGSR and OpenXRay, it's so tempting to do crazy stuff and features) Sure, I'll let you know when the tmc branch becomes stable, I hope there'll be no hard blockers. |
Beta Was this translation helpful? Give feedback.
-
|
I've seen you're planning to introduce an option to make TMC fully header-only, could you maybe make it a tri-state, where the third option would make it header-only, but leave the hwloc-related functionality in ipp which I'd need to define in a .cpp file? I wouldn't probably be so critical against it if hwloc headers didn't include this horrendous windows.h. I'm planning to get rid of including it project-wide in future (vanilla engine code legacy), but give a chance to header-only TMC. As project-wide windows.h is a very bad idea. |
Beta Was this translation helpful? Give feedback.
-
|
I know it's not your problem and I (and other users) should be more careful, so not asking for any changes, just curious... Is When I refactor something like void process_events()
{
// ...
}
// to
tmc::task<void> process_events()
{
// ...
}then the compiler will notify me if I missed a But when changing bool net_spawn()
{
// ...
}
// to
tmc::task<bool> net_spawn()
{
// ...
}
// later
if (!net_spawn())
//then unfortunately the compiler is not able to catch a missing I shot myself in the foot a couple times already, fortunately it was easy to find and fix. |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, I already ran into some issues with |
Beta Was this translation helpful? Give feedback.
-
|
I have seen operator bool be the source of so many subtle bugs. |
Beta Was this translation helpful? Give feedback.
-
|
I made I wish C++ had more advanced |
Beta Was this translation helpful? Give feedback.
-
|
I was just trying to match the API of std::coroutine_handle which has operator bool. Yes, there's no way to create a linear type in C++ at compile time. However there is a debug assert that would fire at runtime in that scenario. I know your project's debug build is broken. Somewhere on my offline TODO list was a custom assert macro so the user can opt-in to having runtime asserts in release builds. I can promote this to an enhancement issue. |
Beta Was this translation helpful? Give feedback.
-
|
The engine contains a whole set of different debug macros; even if the Debug config doesn't work, I can undefine |
Beta Was this translation helpful? Give feedback.
-
|
Hey, I've noticed the development of TMC has slowed down a bunch lately. Just wanted to make sure you are fine, no burnouts, no motivation loss, no problems in real life etc. Take care! (also seems like libfork has finally woken up, I'm curious what the new version will offer, although I'll stay with TMC with no doubts) |
Beta Was this translation helpful? Give feedback.
-
|
Taking a bit of a break after v1.4 release. I've started a new (secret) project that uses TMC so it's good to be dogfooding a bit - helps me find the rough edges or missing functionality. I'll come around and finish v1.5 (mostly finalizing the build system) at some point. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Can I ask a few silly questions since I'm new to coroutines, but eager to switch my oneTBB-based engine to TMC?
aw_spawn_forkin a global struct and co_await it later from some other coroutine, not the one that spawned it?(my assumption comes from that
aw_spawn_forkdoesn't have a default constructor, so putting it in a struct is tricky. Moreover, you mentioned in the docs that they contain pointers tothis, which I got at "you must alwaysco_awaitthe results offork()within the coroutine that spawned them").What would be the best way for the following scenario:
Currently, I run two
task_groups from the former and them wait for them from the latter.task_groups lay in a shared struct, I don't pass pointers for them around the code.I'd like to not use
post_awaitable()and them block on the futures later, since that's not what coroutines are about.I thought of something like:
detach()them immediatelyco_awaitthe condvar/barrier to suspend instead of blocking in case they are not ready yet.But will this guarantee that the coroutines which I'm waiting for will execute for sure even if someone has 1 core and everything executes serially there?
And this doesn't look like an intended/obvious way...
Since
aw_mutexandex_braiddo nearly the same stuff, which one is faster from your code PoV? Mutex seems to be a bit heavier since it builds an awaiters list and need to repost every awaiter on each unlock? But if the contention is really narrow and it's unlikely for this mutex to be blocked,ex_braidcan incur more overhead?aw_mutexhasunlock()andco_unlock(). The latter can do sync transfer. Can sync transfer lead to that let's say 8 threads suspended on the same lock, but, if usingco_unlock(), these 8 coroutines will continue execution on only one thread serially even after this mutex' scope?If I have the following tree of function calls:
Does it mean that if I want to run a coroutine from
f3(), I need to callpost*()from it, even though it's still run onex_cpualready, but doesn't have a suspension point? Or, the preferred alternative would be to convert each of those functions to a coroutine?My main idea is to not block any of the coroutines I want to introduce with serial stuff like generic mutexes/futures/etc, so that only one thread (which runs main synchronous code) could be blocked at a time.
std::hardware_destructive_interference_sizeinstead of hardcoding to 64, it's a constexpr IIRC.But I've also seen that some developers started multiplying it by two since modern CPUs (at least x86_64) often tend to fetch 2 CLs at a time instead of one which could still provoke false-sharing.
Anyway, only benchmarking could give a reliable answer here.
Beta Was this translation helpful? Give feedback.
All reactions