[WIP] Libdeflate #83
[WIP] Libdeflate #83
Conversation
- Because, in the overzooming case, we are very likely to throw out points this reserve is going to over-allocate leading to CPU time requesting memory that will never be used and holding onto more memory than is needed - So, it makese sense to avoid calling this to ensure that the overzooming case is fast - Note: the same advantage is not the same with lines or polygons because we currently have no code that filters them. Rather they need to be fully constructed and therefore the reserve used in those handlers makes sense.
|
With With this branch (using libdeflate): |
|
Noting that @millzpaugh found that in downstream deps this hit problems that would need investigation (and likely fixes in the upstream gzip-hpp PR at mapbox/gzip-hpp#25) including: |
…373: exit: : numeric argument required)
|
@artemp awesome that this is coming together. Can you post benchmarks from your machine of how fast this is compared to |
|
/cc @springmeyer @mapsam @millzpaugh @norchard @jinnycho503 NOTE: bench ran on battery powered laptop so no CPU accelerations. mastertime node bench/bench.js --iterations 50 --concurrency 1 --package vtcomposite --compress --mem
1: single tile in/out ... 251 runs/s (199ms)
2: two different tiles at the same zoom level, zero buffer ... 21 runs/s (2364ms)
3: two different tiles from different zoom levels (separated by one zoom), zero buffer ... 22 runs/s (2305ms)
4: two different tiles from different zoom levels (separated by more than one zoom), zero buffer ... 23 runs/s (2195ms)
5: tiles completely made of points, overzooming, no properties ... 1042 runs/s (48ms)
6: tiles completely made of points, same zoom, no properties ... 962 runs/s (52ms)
7: tiles completely made of points, overzoooming, lots of properties ... 714 runs/s (70ms)
8: tiles completely made of points, same zoom, lots of properties ... 296 runs/s (169ms)
9: buffer_size 128 - tiles completely made of points, same zoom, lots of properties ... 296 runs/s (169ms)
10: tiles completely made of linestrings, overzooming and lots of properties ... 336 runs/s (149ms)
11: tiles completely made of polygons, overzooming and lots of properties ... 141 runs/s (354ms)
12: tiles completely made of points and linestrings, overzooming and lots of properties ... 3333 runs/s (15ms)
13: buffer_size 128 - tiles completely made of points and linestrings, overzooming and lots of properties ... 3571 runs/s (14ms)
14: tiles completely made of points and linestrings, overzooming (2x) and lots of properties ... 5000 runs/s (10ms)
15: tiles completely made of polygons, overzooming and lots of properties ... 446 runs/s (112ms)
16: tiles completely made of polygons, overzooming (2x) and lots of properties ... 847 runs/s (59ms)
17: buffer_size 4096 - tiles completely made of polygons, overzooming (2x) and lots of properties ... 459 runs/s (109ms)
Benchmark peak mem (max_rss, max_heap, max_heap_total): 170.55MB 6.45MB 10.33MB
Benchmark iterations: 50 concurrency: 1
real 0m8.573s
user 0m8.707s
sys 0m0.092slibdefalte (N-API)time node bench/bench.js --iterations 50 --concurrency 1 --package vtcomposite --compress --mem
1: single tile in/out ... 316 runs/s (158ms)
2: two different tiles at the same zoom level, zero buffer ... 54 runs/s (931ms)
3: two different tiles from different zoom levels (separated by one zoom), zero buffer ... 51 runs/s (982ms)
4: two different tiles from different zoom levels (separated by more than one zoom), zero buffer ... 56 runs/s (900ms)
5: tiles completely made of points, overzooming, no properties ... 2000 runs/s (25ms)
6: tiles completely made of points, same zoom, no properties ... 1667 runs/s (30ms)
7: tiles completely made of points, overzoooming, lots of properties ... 1282 runs/s (39ms)
8: tiles completely made of points, same zoom, lots of properties ... 820 runs/s (61ms)
9: buffer_size 128 - tiles completely made of points, same zoom, lots of properties ... 820 runs/s (61ms)
10: tiles completely made of linestrings, overzooming and lots of properties ... 602 runs/s (83ms)
11: tiles completely made of polygons, overzooming and lots of properties ... 174 runs/s (287ms)
12: tiles completely made of points and linestrings, overzooming and lots of properties ... 5000 runs/s (10ms)
13: buffer_size 128 - tiles completely made of points and linestrings, overzooming and lots of properties ... 4545 runs/s (11ms)
14: tiles completely made of points and linestrings, overzooming (2x) and lots of properties ... 7143 runs/s (7ms)
15: tiles completely made of polygons, overzooming and lots of properties ... 543 runs/s (92ms)
16: tiles completely made of polygons, overzooming (2x) and lots of properties ... 1042 runs/s (48ms)
17: buffer_size 4096 - tiles completely made of polygons, overzooming (2x) and lots of properties ... 562 runs/s (89ms)
Benchmark peak mem (max_rss, max_heap, max_heap_total): 185.65MB 8.19MB 13.23MB
Benchmark iterations: 50 concurrency: 1
real 0m4.044s
user 0m4.110s
sys 0m0.085s |
|
@vakila 👋 here's the PR I mentioned to you that we'd love a quick hand testing on linux: Post results. Then do: Then post results. |
|
@springmeyer 👋 Here you go! Nothing like a little benchmarking to make time fly while waiting at the airport 😁 For the record this was on Ubuntu 16.04 on a ThinkPad X1 i7. Also for the record I had to run Let me know if you need any other info, hope this helps! |
|
Wonderful thanks @vakila! Thank confirms perf is nearly 2x faster on linux as well as OS X 🎉 for this branch. Have a great 🛫 ! |
|
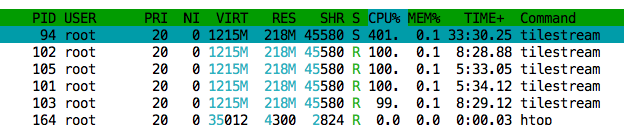
@artemp I tested this in a production-like environment today with production-like load. Unfortunately it was significantly slower (2x) than the normal
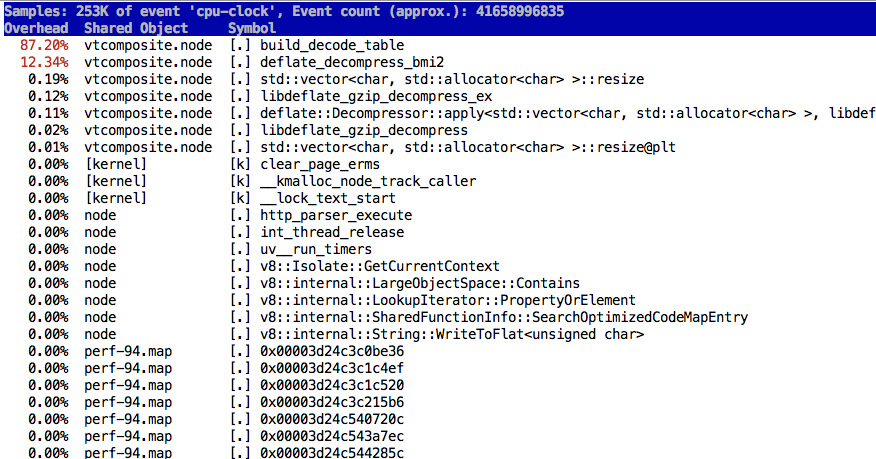
I profiled with
I think I see why this is happening:
Given ebiggers/libdeflate@268d2fe it seems like we can't just initialize |
|
On further investigation it actually looks like the threads are hung on |
… + 2x output size on LIBDEFLATE_INSUFFICIENT_SPACE + removed LIBDEFLATE_SHORT_OUTPUT case as we're always passing non NULL actual_size [publish binary]
|
@springmeyer - I modified how de-compressor allocates output size and also refactored code a bit in f0016e3 |
…d storing `Napi::Reference<Napi::Buffer<char>>` in TileObject.
|
Closing to close this. Probably has merit still since it provided a performance boost. But in practice, if I recall correctly, the performance boost was not enough to warrant the potential risk (in production systems that work without problems currently as far as zlib compression) in switching the implementation. |
This makes changes to vtcomposite to build locally against mapbox/gzip-hpp#25.