An AI-powered tool for deep document understanding, Q&A, and logic-based challenge generation from user-uploaded research papers, reports, and technical documents.

- Upload PDF/TXT documents
- Auto-summary (≤150 words)
- Ask Anything: Free-form Q&A with references
- Challenge Me: Logic-based questions, answer evaluation, and feedback
- All answers are grounded in the uploaded document
- Modern, responsive web UI (React)
- Multi-provider LLM support (OpenAI, Gemini, Claude, Local)
cd backend
pip install -r requirements.txt
python download_models.py # Download required AI models
python main.py # Start backend server (http://localhost:8000)After running the backend you should see a confirmation message like this:

after seeing the confirmation message only you can make calls to backend otherwise it will be error.
cd frontend
npm install
npm run dev # Start frontend (http://localhost:5173)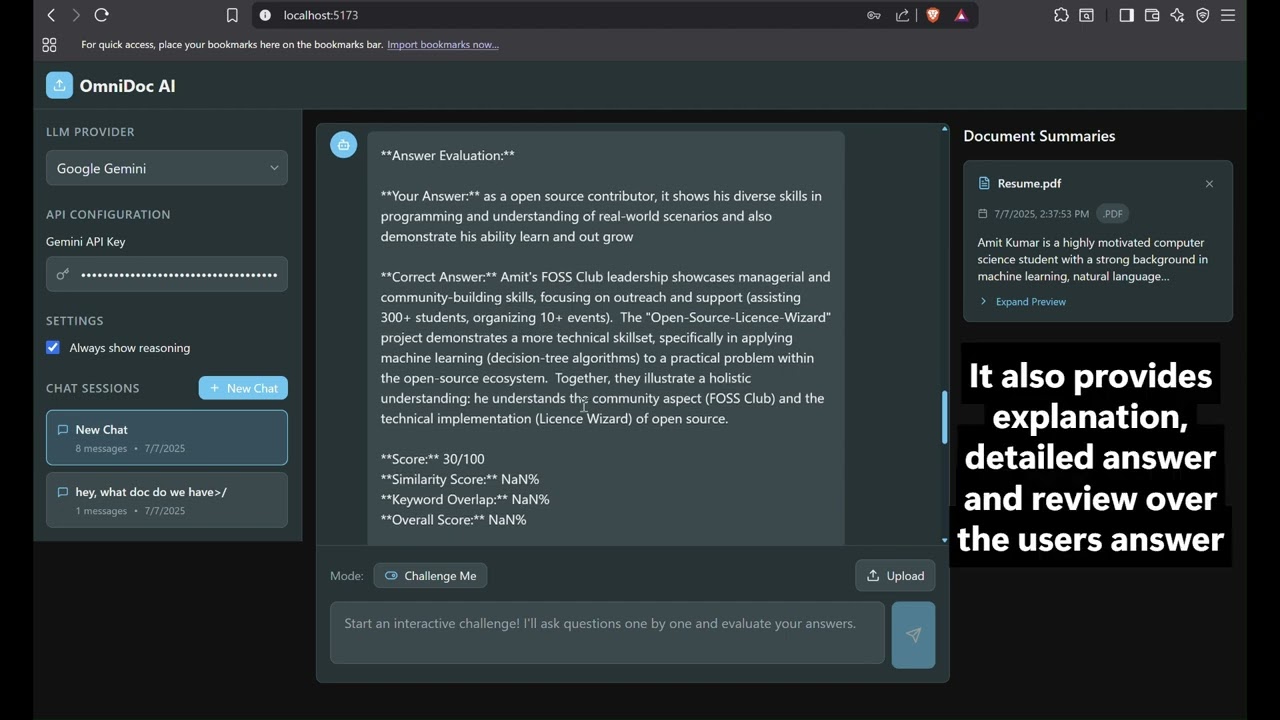
- Upload a PDF/TXT document
- View the auto-generated summary
- Use "Ask Anything" for Q&A
- Use "Challenge Me" for logic-based questions and feedback
- All answers include references to the document
- Add your LLM API keys in the sidebar (frontend) or in
backend/.env - Supported: OpenAI, Google Gemini, Anthropic Claude, Local LLM
OmniDoc-AI/
├── backend/
│ ├── api/
│ ├── services/
│ ├── chroma_db/
│ ├── main.py
│ └── requirements.txt
├── frontend/
│ ├── src/
│ └── package.json
├── tests/
├── README.md
└── QUICKSTART.md
- Frontend: React (with Tailwind CSS) for a modern, responsive UI. Handles document upload, mode selection ("Ask Anything" or "Challenge Me"), and displays answers, references, and reasoning.
- Backend: FastAPI, responsible for document parsing, chunking, embedding, hybrid retrieval (ChromaDB), and LLM orchestration (OpenAI, Gemini, Claude, or local models).
- Vector DB: ChromaDB stores semantic and keyword embeddings for all uploaded documents, enabling fast and accurate retrieval.
-
Document Upload
- User uploads a PDF or TXT file via the frontend.
- Backend parses the document, extracts structure, splits into semantic chunks, and stores embeddings in ChromaDB.
- An auto-summary (≤150 words) is generated and displayed immediately.
-
Interaction Modes
- Ask Anything:
- User asks a free-form question.
- Backend performs hybrid retrieval (dense + keyword) to find the most relevant document chunks.
- LLM is prompted with only the retrieved context.
- The answer includes:
- Direct response
- Step-by-step reasoning (reasoning chain)
- Specific references/snippets from the document
- Challenge Me:
- System generates three logic-based or comprehension questions from the document.
- User answers each question.
- Backend evaluates the answer, provides a score, feedback, and references to the supporting document content.
- Ask Anything:
-
Justification & Context
- Every answer and evaluation includes:
- A reference to the supporting document section (e.g., "Page 2, Section 1.3" or snippet preview)
- A brief justification or reasoning chain
- The system avoids hallucination by grounding all responses in retrieved document content.
- Every answer and evaluation includes:
-
Session & Memory
- The frontend maintains session context, allowing for follow-up questions and persistent chat history.
- Each message can display the reasoning chain and supporting snippets.
- User uploads a research paper.
- User asks: "What is the main finding of this paper?"
- Backend retrieves the most relevant chunks using hybrid search.
- LLM is prompted with:
- The user's question
- The retrieved context
- Instructions to answer only using the provided context and to cite references
- LLM returns:
- Answer: "The main finding is X."
- References: "Page 3, Section 2.1"
- Reasoning: "This is supported by the summary in Section 2.1, which states..."
- User uploads a technical manual.
- User selects "Challenge Me."
- System generates three logic-based questions (e.g., "Explain the process described in Section 4.2").
- User answers; backend evaluates each answer, provides a score, feedback, and references.
| Issue | Solution |
|---|---|
| Backend won't start | Run python download_models.py in backend |
| Frontend can't connect | Make sure backend is running on port 8000 |
| Model download slow | Wait for first run; models are cached |
| Port already in use | Change port in main.py or frontend config |
| ChromaDB errors | Delete chroma_db/ and restart backend |
cd tests
pytest # or python test_backend.py