Ecommerce-Scraper is an open-source project that aims to scrape data from e-commerce websites such as Amazon and Flipkart. It is built using the Scrapy framework and Python and is designed to be used for price comparison and product research purposes.
To use Ecommerce-Scraper, you will need to have Scrapy and Python installed on your machine. To install the project, follow these steps:
- Clone the repository:
git clone https://github.com/ShauryaSwarup/Ecommerce-Scraper.git - Install the dependencies:
pip install -r requirements.txt - Run the project:
- Using the bash script (easy):
- Give executable permissions to bash script:
chmod +x ./script - Run the bash script
./script
- Give executable permissions to bash script:
- Using the python script: Run the main function
python3 main.py
- Using the bash script (easy):
Ecommerce-Scraper can be used as an API service to scrape data from Amazon and Flipkart and you can also export the data in a json format if required. Future work also includes scraping and crawling more e-commerce websites. We can also crawl more types or categories like laptops, accessories, footwear and more.
Scrapy is a highly efficient library. It's an open-source collaborative framework for extracting the data we need from websites. It has a quick response time. Scrapy includes support for extracting data from HTML or XML sources using CSS and XPath expressions.
Scrapy is a full-fledged web scraper framework. You can start scraping by providing Scrapy with a root URL, then specifying how many URLs you want to crawl and fetch, and so on.
- It is easily extensible.
- It has built-in support for extracting data.
- It has very fast speed compared to other libraries.
- It is both memory and CPU efficient.
- You can also build robust and extensive applications.
- Has strong community support.
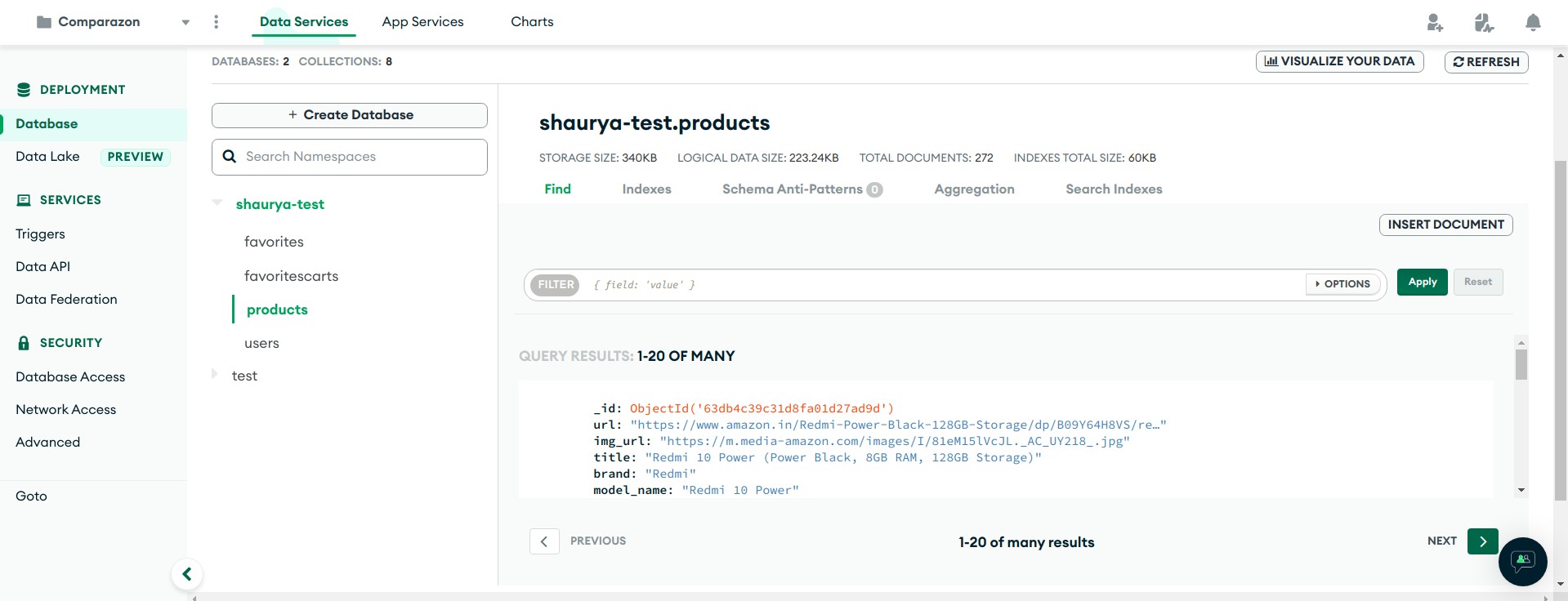
- Scrapes product details such as name, price, colour, storage, image URL and many more details just from the title thus the scraper is very efficient in terms of time and memory. [300 products in 15-20 seconds without a proxy service, 30-40 seconds with a rotating proxy service]
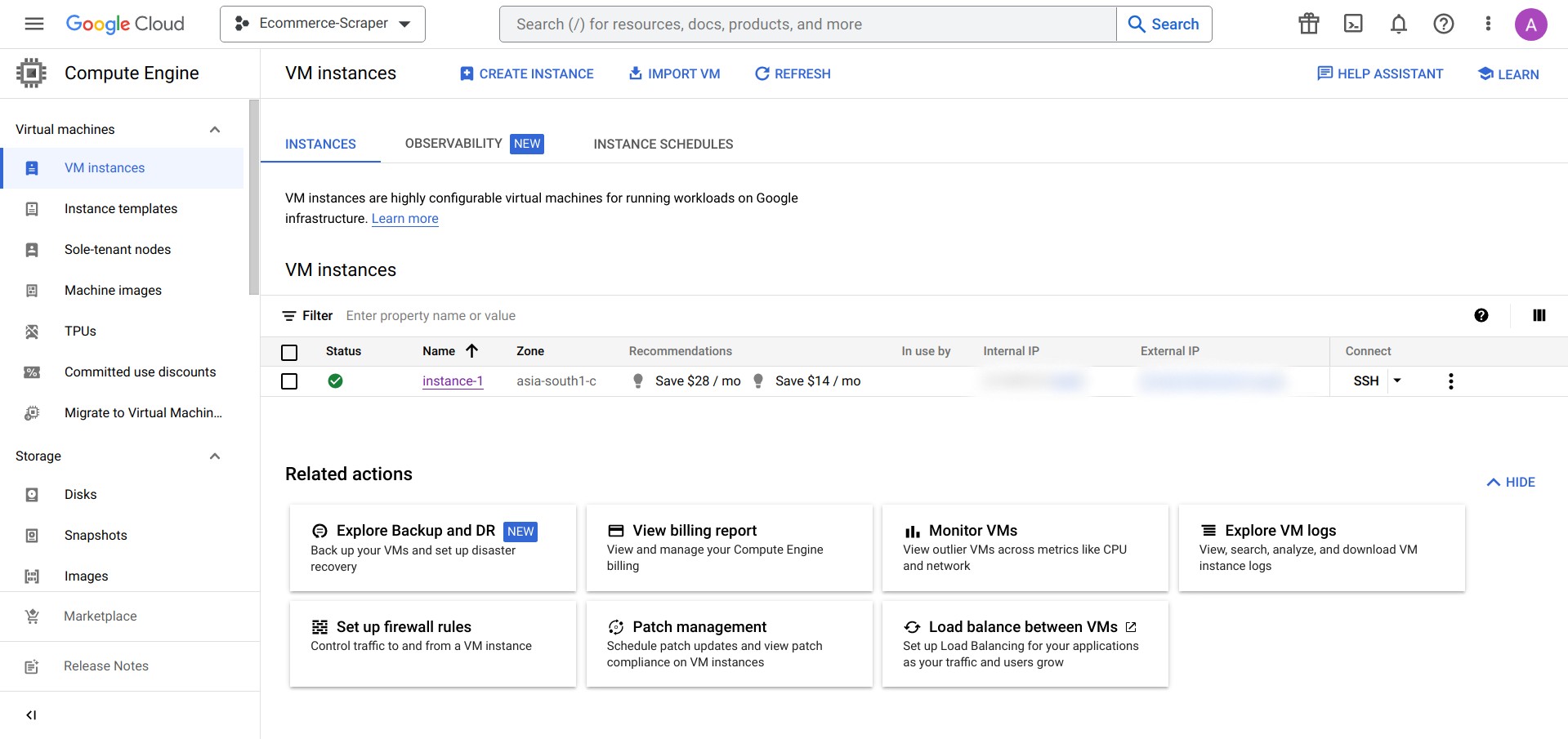
- Can be scheduled to run on a daily basis on a cloud service or server or using a service like ScrapeOps
- Running a cronjob on the VM Instance on Cloud (I use a VM Instance Google Cloud Platform)
- Uses ScraperAPI for rotating proxies to avoid Amazon blocking the crawler
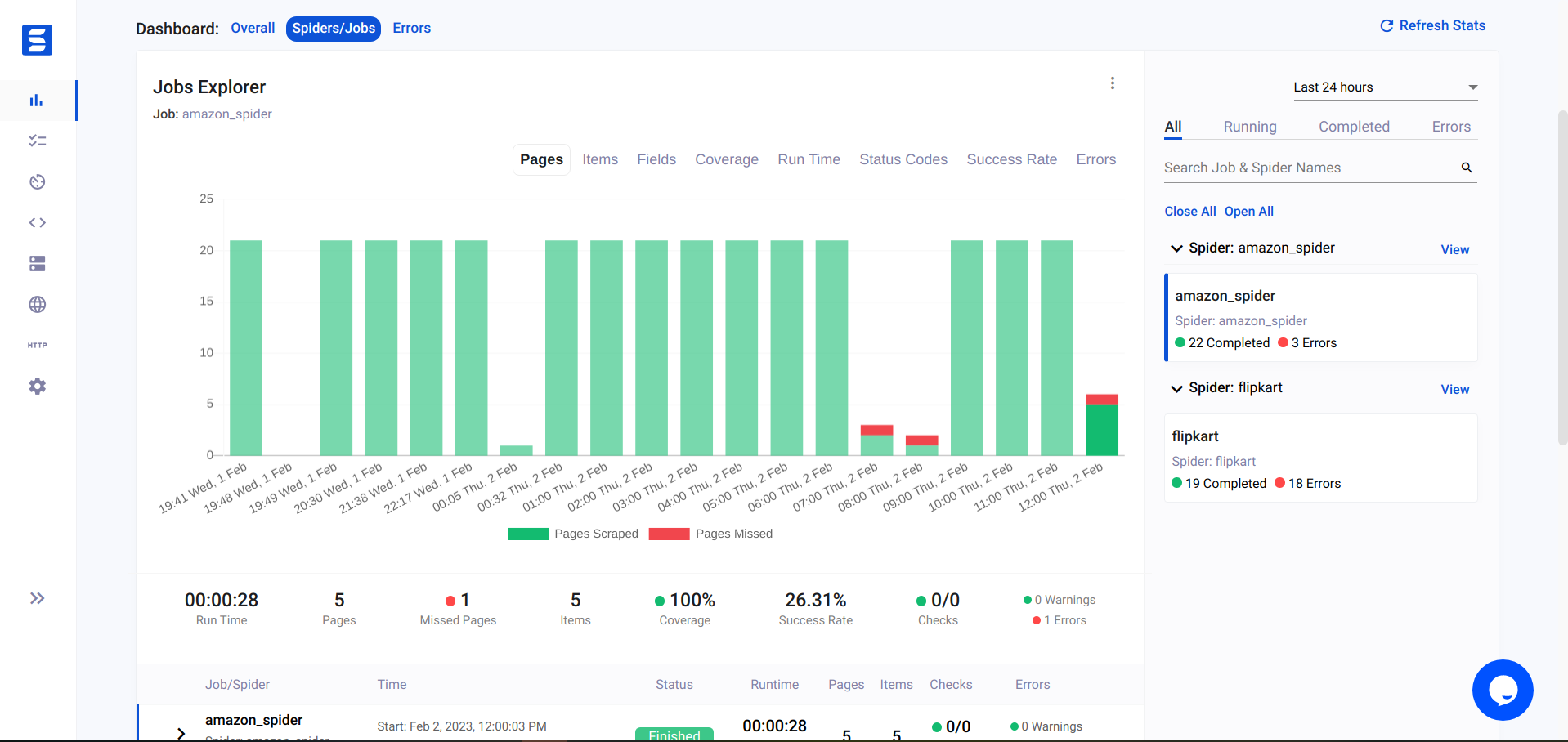
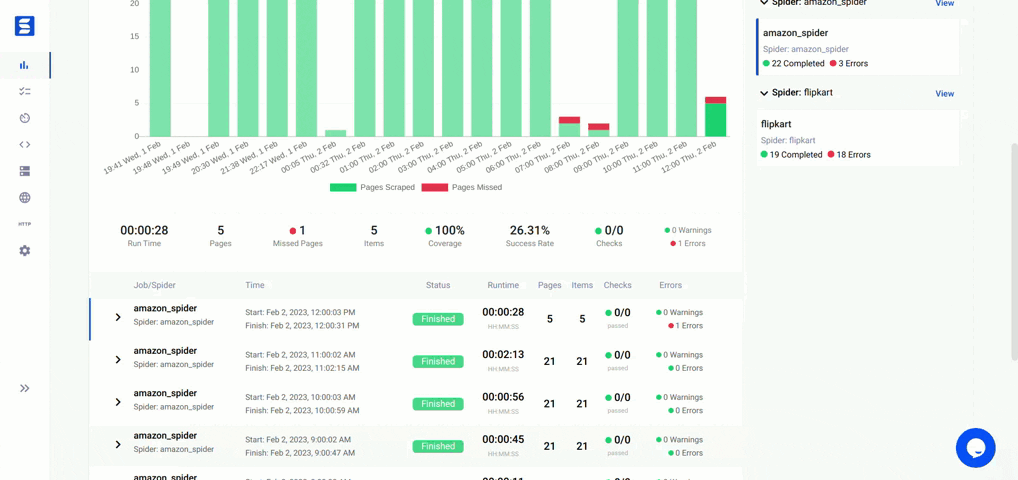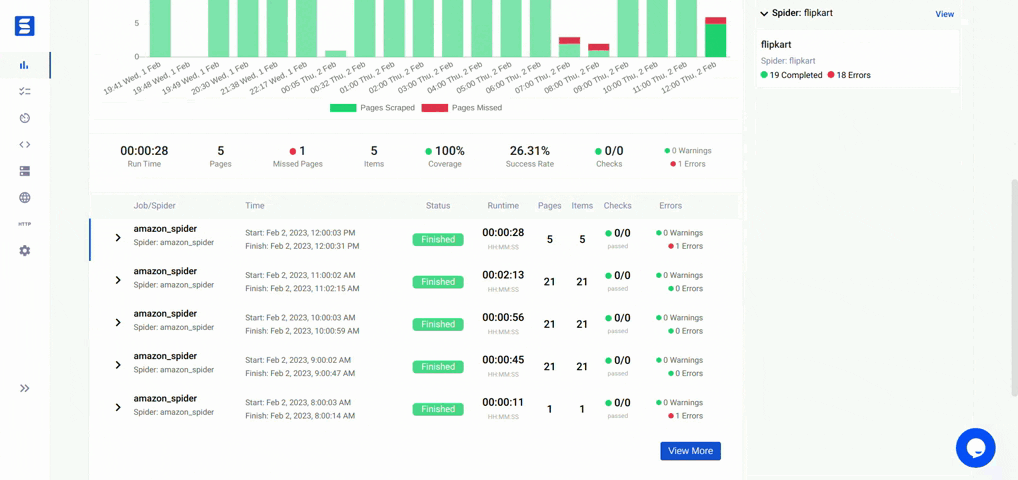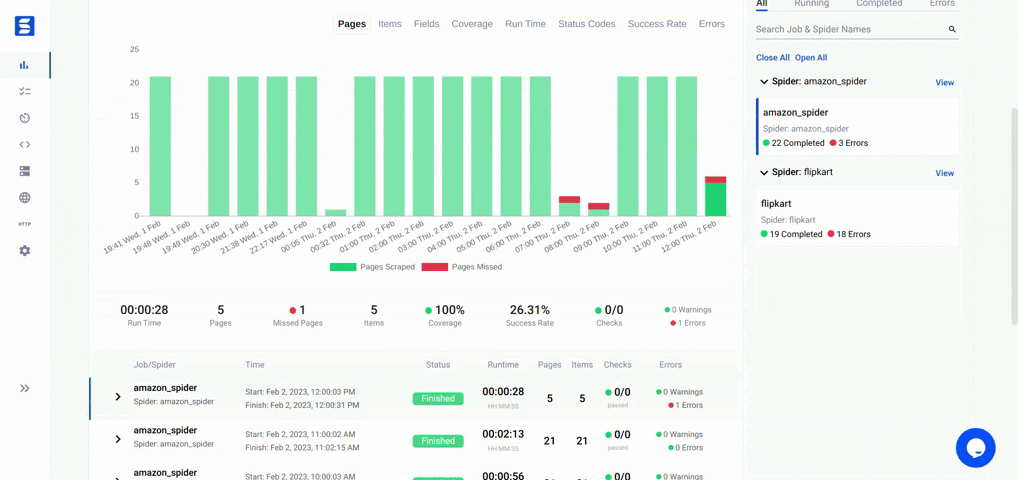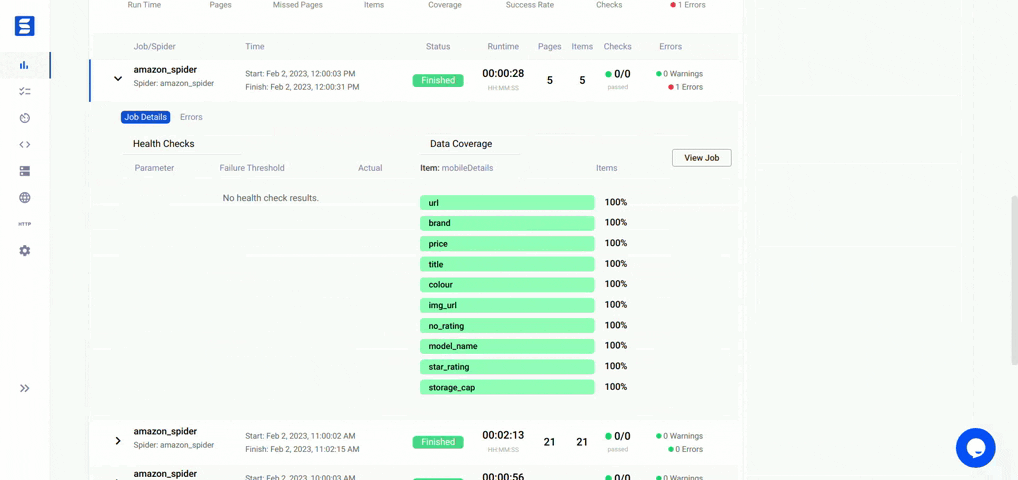

If you are interested in contributing to Ecommerce-Scraper, please follow these guidelines:
- Fork the repository
- Create a new branch for your feature
- Submit a pull request
Ecommerce-Scraper is licensed under the GNU General Public License v3.0. This means that you are free to use, modify, and distribute the code as long as you adhere to the terms of the license.
If you have any questions or feedback, please feel free to reach out to me at [email protected]
Thank you for using Ecommerce-Scraper!