김동욱, 정보시스템학과 ([email protected]) 이재흠, 컴퓨터소프트웨어학과 ([email protected])
김동욱: 동기&목표, 방법론, 딥러닝, 녹음 이재흠: 동기&목표, 데이터 전 처리 & 분석
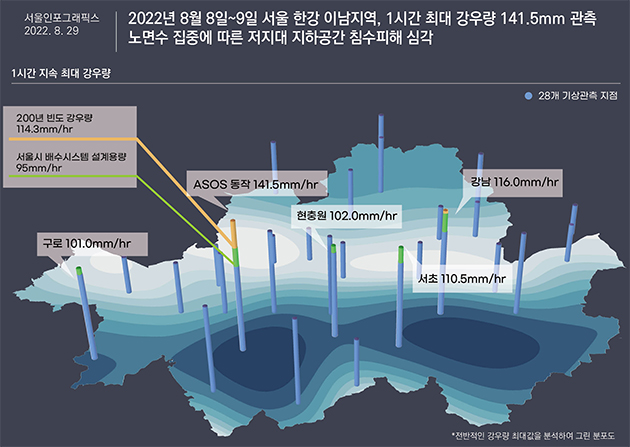
2022년 8월, 서울 시내에서는 기록적인 폭우가 내렸습니다. 이번 폭우의 1시간 최대 강수량은 141.5로 예상보다 훨씬 웃도는 수치였습니다. 이는 호우주의보가 내려지는 60mm/3hr 를 훨씬 넘어선 수치입니다.
이번 폭우로 인해 건물이 무너지거나 마저 대피하지 못한 사람들이 피해를 입었습니다.
또한 지하철 침수 피해로 많은 사람이 퇴근길에 귀가를 하지 못하는 불편함을 겪었습니다.
반지하에 살던 사람이 목숨을 잃게 되는 비극적인 일까지 일어났습니다.
이 폭우가 일어나기 전 사람들은 비가 올것 이라는 사실은 알고 있었으나, 기록적인 폭우가 내려 많은 피해가 날거라고는 예상하지 못하였습니다. 만약에 폭우가 오기 전에 일정한 규칙이 있고, 이를 알아내어 폭우를 예측할 수 있었다면, 사람들이 미리 대비하여 어느정도 피해를 막을 수 있었다고 생각합니다.
따라서 저희 팀은 딥러닝을 통해 폭우를 미리 예측하여 재난에 대응할 수 있는 가능성을 만들어보고자 합니다.
폭우를 예측하기 위해 필요한 데이터 셋에서 고려해야 할 사항을 생각해보았습니다. 데이터셋에서 고려해야 할 사항은 크게 세가지 입니다.
- 누락, 정확성, 접근성
- 파라미터 종류 (강수량, 기온)
- 관측 간격
데이터 셋 중에는 특정 년도가 누락되어 시간이 몇개월 사라져있거나, 시간이 나와있어도 강수량이 누락되어있는 경우가 있었다. 또한 관측기계의 오류나 주변 환경의 이상현상 등으로 이상치가 나오는 데이터도 있음을 주의하여 데이터 셋을 수집하였다.
관측값의 종류 : 처음에는 최대한 다양한 파라미터 값을 가지고 있는 데이터 셋을 가지려 노력해 보았으나, 이러한 값은 얻기 힘들었다. 무엇보다 값이 다양할 수록 지역이 서울 전체이거나 관측간격이 하루간격인 경우등 다른 요소를 잃는 데이터 셋이 대부분이었기에, 관측 간격을 먼저 고려하고 그 후 데이터셋 별로 비교해보기로 하였다.
지역의 범위, 종류 : 초기에는 서울시의 날씨 값을 가져오는 데이터를 사용하려고 했으나, 서울의 면적과 서울 각 지역별 날씨의 차이가 있음을 고려해야했다. 서울을 각 지역별로 나누어 파라미터 값을 더 많게 만들거나, 서울에서 특정 지역으로 축소하는 방법으로 이 문제를 해결할 수 있었다. 이 중에서 서울시이었던 지역을 성동구 한 지역으로 축소해 데이터셋을 얻기로 하였다.
찾았던 데이터셋 중 가장 많은 관측 간격이었던 하루 간격의 경우, 폭우를 예측하기에는 너무 간격이 커 정확도가 떨어져 더 짧은 간격으로 구해보기로 하였다. 1분 간격과 1시간 간격의 데이터를 얻을 수 있었지만, 1분 간격의 경우 측정된 강우량이 너무 적어 (1분간 내린 강우량이 측정되었다) 폭우를 인식하는데 무리가 있다고 느껴 1시간 간격으로 결정하였고, 1시간 간격도 짧다고 느껴지면 데이터셋을 뭉쳐 2~6시간 간격으로 되어있는 값을 구해보기로 하였다.
이런 상황을 고려해보았을 때, 1시간 간격의 기상청 지역별상세관측자료(AWS)를 이용하기로 하였다. 이 데이터 셋은 2000년대부터 기상관측자료를 수집해오고 있어 방대한 양의 데이터 셋을 얻을 수 있었다.
실시간 AWS, csv형태로 제공하지 않아 데이터를 얻을려면 크롤링을 해주어야 한다.
위 자료를 정리해놓은 사이트 (많이 느림) → 다운 완료(분, 시간, 일단위)
기상자료개방포털[데이터:기상관측:지상:방재기상관측(AWS):파일셋]
하루단위의 데이터 셋
날씨 데이터 셋(2010년대부터 멈춘듯)
날씨 관련 데이터셋(1시간 단위, 유료), 유료이다.
Weather Archive Seoul - meteoblue
강우량 (10분단위, 서울 지역별), 기간이 2021년까지 밖에 제공이 안된다.
이번 프로젝트의 목표는 폭우를 예측하는 것입니다.
저희 팀은 현 날짜까지의 강수량 데이터를 모았고 이 데이터를 기반으로 미래의 데이터를 예측해보고자 합니다.
RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 갖고있습니다.
이는 곧 이전의 작업을 현재와 연결시킬 수 있고 이전의 데이터를 기반으로 상황에 맞는 결과를 낼 수 있다는 의미이기도 합니다.
따라서 RNN을 이용하면 이전의 강수량을 통해 현재의 강수량을 알 수 있습니다.
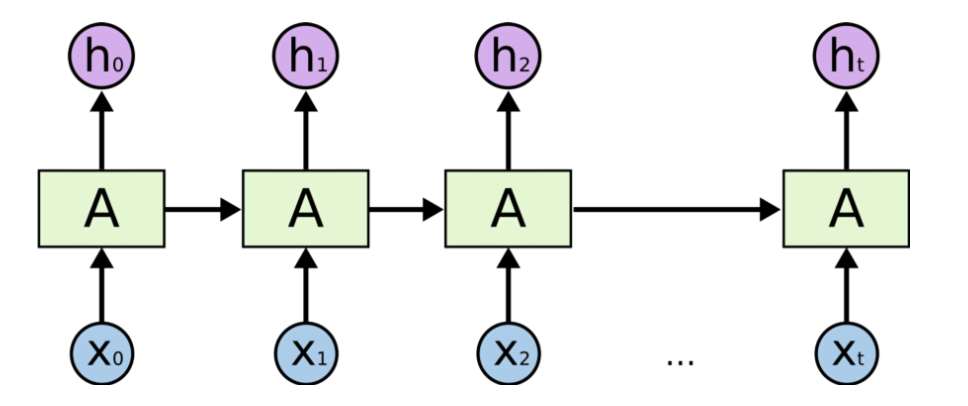
<RNN의 구조도>
RNN은 gradient 계산에서 곱셈 연산을 하는데 1보다 작은 값을 계속 곱하면서 결국 gradient는 0으로 수렴합니다.
이를 경사 소실 문제라고 합니다.
저희의 프로젝트에서는 약 20년 간의 데이터를 다루며 이는 경사 소실 문제로 이어질 수 있습니다.
이를 해결하기 위해 LSTM을 사용하기로 했습니다.
LSTM은 RNN의 한 종류이며 곱하기 연산이 아닌 더하기 연산을 사용합니다.
실제로 LSTM은 RNN 보다 훨씬 향상된 성능을 보여주며 이는 저희의 프로젝트에 적합해 보입니다.
reference.
Long Short-Term Memory (LSTM) 이해하기
챕터 2에서 찾은 기상청 지역별상세관측자료로 데이터 분석을 해보았다. 폭우를 예측해야 하기 때문에, 기상청에서 폭우를 어떤 기준으로 결정하는지 확인해보기로 하였다.
☔ 6시간에 누적강수량이 **70mm** 이상 또는 12시간에 누적강수량이 **110mm** 이상 예상될 때 호우주의보를 발표한다.이를 토대로 시간 간격을 6시간, 3시간, 2시간, 1시간으로 묶는 방법을 생각해 볼 수 있었다. 시간이 적을수록 폭우에 대한 민감도가 늘어나는 대신, 실제로 폭우인지에 대한 정확도는 떨어진다. 따라서 이 중 3시간 간격으로 데이터를 묶는 방법을 사용하기로 하였다.
얻은 데이터 중에서는 일사, 일조, 현지기압, 해면기압의 경우 특정 년도에 누락된 값이 있어 모델에 넣는 파라미터 값에서 제외시키기로 결정하였다.
- 데이터 파일
-
1시간 단위 (날짜 누락 없음)
-
3시간 단위
-
일단 1일 단위로 나누어져 있는 데이터를 가져와 학습시켜보았습니다.
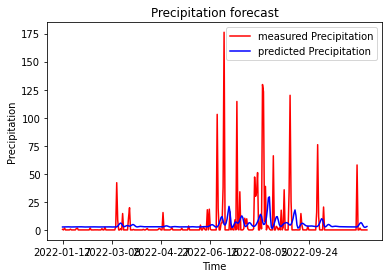
다음과 같은 결과가 나왔습니다
아마 0으로 돼있는 데이터가 너무 많고
최솟 값인 0과 최댓 값인 175의 차이가 정규화를 했다하더라도 너무 큰게 원인이 아닐까 생각됩니다.
하지만 정점의 x값 위치가 예측 데이터와 실제 측정 데이터가 비슷하기에 아주 의미 없는 데이터라 보기엔 힘듭니다.
3시간 단위의 데이터를 ephoc 50, batchSize 512로 학습시켜봤습니다.
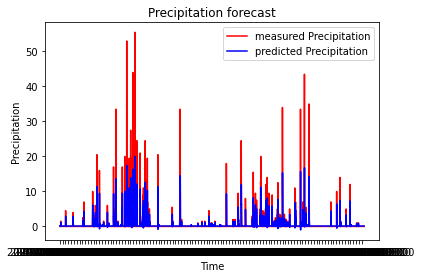
최댓 값과 최솟 값의 차가 줄어들어서 인지 아니면 하루 단위의 데이터가 3시간 단위로 바뀌며
학습 데이터가 많아져서 인지 전보다 좋은 결과를 보였습니다.
3시간 단위 데이터를 배치 사이즈를 줄여서 학습시켜봤습니다. (ephoc 100, batchSize 32)
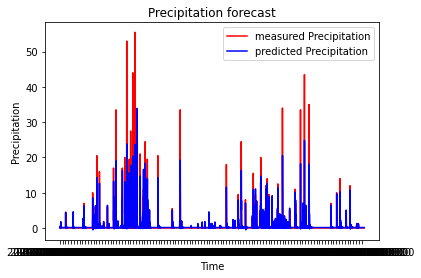
배치 사이즈를 줄이니 더 좋은 성능을 보입니다.
한시간 단위의 데이터도 학습시켜봤습니다.(ephoc 100, batchSize 32)
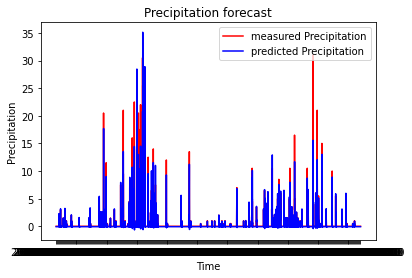
가장 좋은 성능을 보이나 한시간 단위의 데이터는 폭우의 기준을 잡기 어려워
3시간 데이터로 미래를 예측해보기로 했습니다.
reference.
How to Use Features in LSTM Networks for Time Series Forecasting - MachineLearningMastery.com
저희는 앞서 만든 (3시간 단위의,ephoc 100, batchSize 32)모델을 통해 2년간의 강수량을 예측하고자 했습니다.
예측 결과입니다. 이는 테스트 셋에서와는 다르게 매우 좋지 않은 결과로 보입니다.
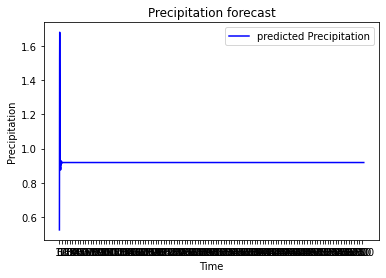
처음에는 잘 예측되는 듯 했으나.

뒤로 갈 수록 비슷한 값만 나오는 현상을 보였습니다.

실패 원인을 분석하는 과정이 필요해 보입니다.
*순전히 저의 의견입니다!
테스트 데이터를 예측하는 알고리즘을 간단하게 나타내면 다음과 같습니다.
반복 N번
[실제 데이터 60개] ⇒ (인공지능) ⇒ [예측데이터 1개]
만약에 제가 인공지능이라고 가정하고 [0 60개]데이터가 들어온다면 저는 [0]을 예측데이터로 반환할 것입니다.
그 예측된 0을 다시 학습 데이터에 넣고 [0 61개] 뒤에서 부터 60개를 자른뒤 [0 60개] 다시 예측을 한다면 다시 [0]이 나옵니다.
따라서 이를 반복하면 0만이 예측 데이터로 나오게 됩니다.
하지만 저희가 테스트 데이터로 사용한 데이터는 0이 연속적으로 60개 이상 나왔음에도 불구하고 좋은 결과를 보였습니다.
그 이유는 “실제 데이터”를 기반으로 예측하기 때문입니다.
테스트 데이터를 예측하는 알고리즘은 [0 60개]데이터가 들어오면 [0]을 예측데이터로 반환한 뒤에
실제 데이터인 [3]을 학습 데이터에 넣고 뒤에서 부터 60개를 잘라 [0 59개 3 1개] 데이터로 다음 값을 예측합니다.
이는 저희가 생각하는 진정한 예측과는 거리가 있어보입니다.
따라서 저희가 진정한 예측을 시도했을 때, 좋지 않은 결과를 얻은 것 같습니다.
테스트 데이터에서는 좋은 결과가 나왔으나 실제로 예측을 하려했을 때, 좋지 않은 결과를 얻었습니다.
lstm을 만약 기온이나 주가처럼 연속적이고 계속 변하는 값을 예측하는 데에 사용하면 효과가 좋을것 같으나.
강수량처럼 항상 측정되는 값이 아니고 계속 변하지 만은 않는 값을 예측하는데에 쓰면 좋지 않은 결과가 나오는거 같습니다.
비록 예측에 실패했으나 좋은 가르침을 얻은것 같습니다.