Going Places With PRAW (Exploring the Toyota Subreddits)
This project aims to acheive the following:
- Extract data from multiple instances of PRAW (Reddit API Wrapper)
- Transform and clean data into an intepretable and loadable format
- Perform NLTK Sentiment algorithim on Reddit Objects
- Scan Reddit objects for instances of user-defined keywords and language taxonomy.
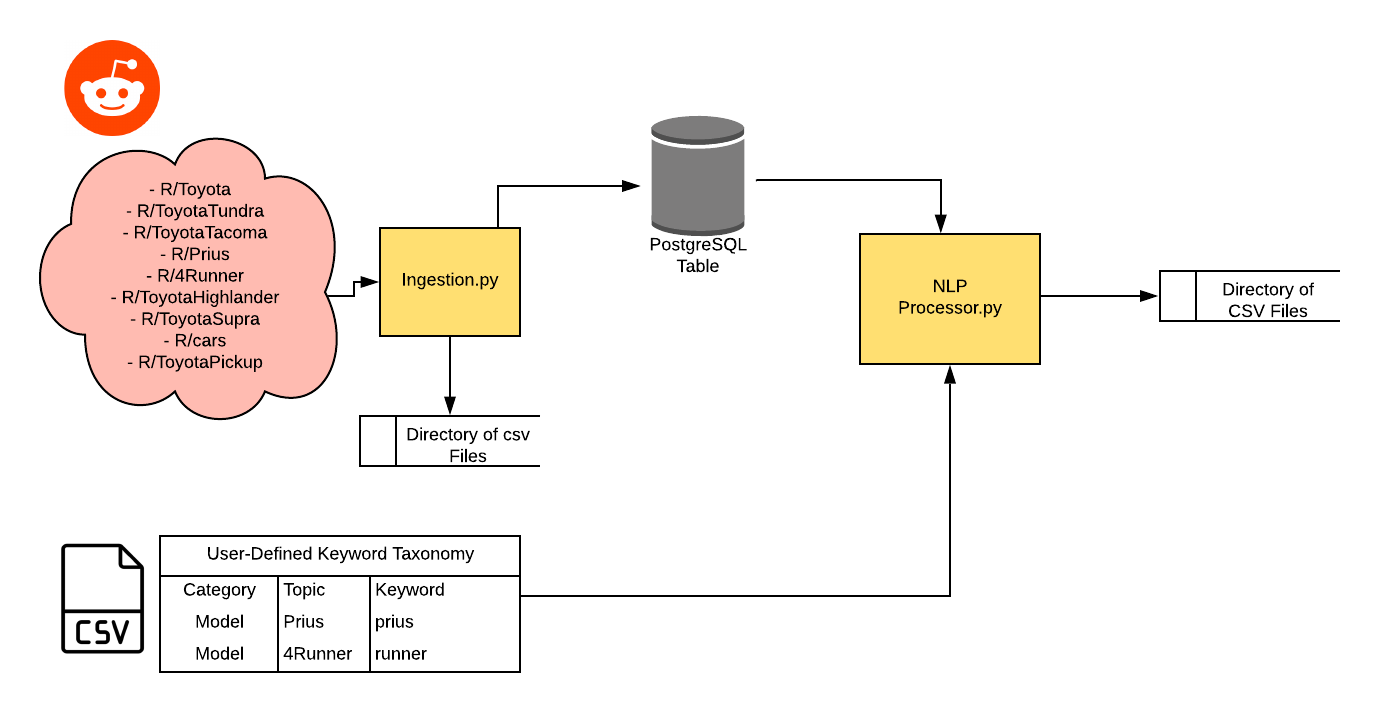
Background:
This project was created from the perspective of a hypothetical social media / customer experience manager who wishes to create a data feed and dashboard that better contextualizes the conversations among members of the Toyota communities. Every day, hundreds of discussions occur across dozens of distinct Toyota communities that cover Q&A, tips and tricks, maintainence, accessories, and more.
This hypothetical user has also modeled a taxonomy of Keywords and Topics that she would like to extract from the PRAW model.
Summary of Problem:
Social media and text data is difficult to analyze with industry standard tools because it often times fails to capture nuance and context of what the user is referencing. In this example, the users are car owners committing to different Subreddits and mentioning problems they are having with their cars, in many cases without explicitly mentioning the model and year. As a social media / CX manager, you would want to understand exactly which year and model customers are referencing when they speak of an issue or potential defect.
Collecting our Data:
For data collection, we will be authenticating via PRAW (https://praw.readthedocs.io/) using the Submission model and collecting from the following subreddits:
- R/Toyota
- R/ToyotaTundra
- R/ToyotaTacoma
- R/Prius
- R/4Runner
- R/ToyotaHighlander
- R/ToyotaSupra
- R/cars
- R/ToyotaPickup
Final Tableau Dashboard:
