Add ablation flags (disable_act, break_recurrence, etc.) to enable depth-extrapolation training#58
Conversation
Adds five opt-in knobs on MythosConfig that expose the mechanisms controlling how each recurrent loop iteration differs from every other. All defaults preserve the original architecture exactly; the diff is a zero-impact addition for users who don't set any of them. - loop_index_embedding (default True): toggle the sin/cos loop-index signal injected into `h` at each step. - use_per_loop_lora (default True): toggle the per-loop LoRA scale. - disable_act (default False): return the final-iteration `h` instead of the ACT-weighted sum over all iterations. - freeze_moe_router (default False): indicate whether MoEFFN.router should be excluded from grad updates; actual requires_grad must be set externally after model construction (kept here on the config so training code has a single source of truth). - break_recurrence (default False): replace the LTI update `h = A·h_t + B·e + trans_out` with `h = trans_out`, killing the state-carry across loops while keeping the transformer block + the `e`-injection via `norm(h + e)`. README gets a new "Depth-extrapolation recipe" section documenting the empirical finding that `disable_act` is the only flag (out of the five above plus LTI-parameter freezing) that qualitatively changes the inference-time loop-scaling curve, and gives the specific training recipe (random `n_loops` per step + `disable_act`) that yields monotonic PPL decrease with inference depth. Full methodology, 13-run ablation, and loop_scaling plots are tracked in kyegomez#28. No changes to model semantics at the default flag values; only new control surface is exposed.
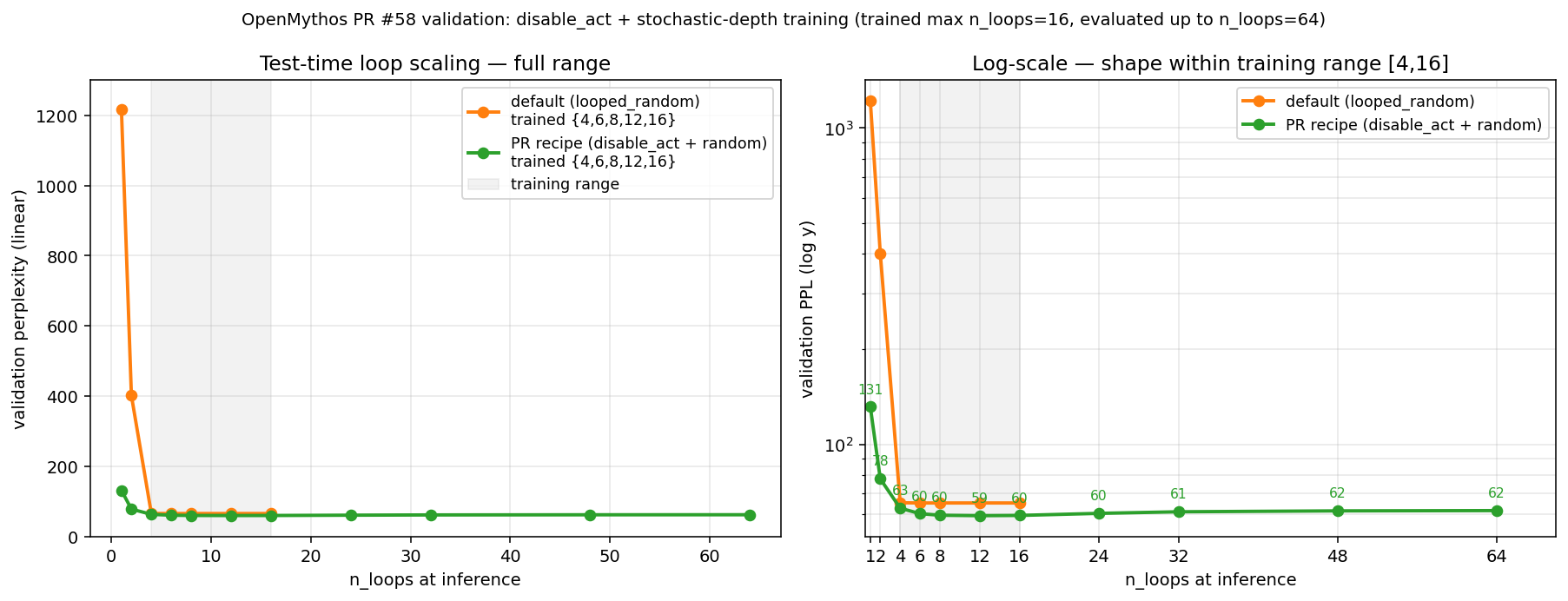
Validation: the recipe extrapolates to 4× training depthRetrained Results (sorted by n_loops)
Key signals
CaveatThe curve is monotonic-decreasing-then-saturating. It's not "more inference loops always keeps helping" — past SummaryThe recipe in this PR's README section — This validates the PR on its stated goal. Raw data: |
|
Hi, With Severity: action required | Category: correctness How to fix: Honor n_loops when disable_act Agent prompt to fix - you can give this to your LLM of choice:
Spotted by Qodo code review - free for open-source projects. |
Summary
Adds five opt-in flags on
MythosConfigthat expose the individual mechanisms controlling how each recurrent loop iteration differs from every other. Defaults preserve the original architecture exactly — this is a zero-semantics-change addition for existing users. The flags exist to make the mechanistic experiments in #28 first-class supported operations rather than external monkey-patches.loop_index_embeddingTruehat each step (makes loops anonymous)use_per_loop_loraTrueLoRAAdapter.scaleapplicationdisable_actFalsehfrom the last loop iteration instead of the ACT-weighted sumfreeze_moe_routerFalseMoEFFN.routerweight should be frozen at initbreak_recurrenceFalseh = A·h_t + B·e + trans_outwithh = trans_out(drop LTI state carry)Why it matters
A 13-run ablation study (same 117.8M MoE+MLA architecture, same ~491M tokens FineWeb-Edu, 4 rounds of experiments totaling ~$150 of H100 time — tracked in #28) found that
disable_actis the only flag out of five tested that qualitatively changes the inference-time loop-scaling curve from the V-shaped / flat-plateau behaviour of the default architecture to a monotonically decreasing-and-saturating curve. Specifically, the combinationdisable_act=True+ stochastic-depth training (samplingn_loopsuniformly per step from e.g.{4,6,8,12,16}) produces:— the only configuration in the 13-run matrix that matches the Saunshi et al. 2025 / Parcae depth-extrapolation shape the README argues for.
What this PR does / doesn't do
Does:
MythosConfig.loop_index_embedding(h, t, …),self.lora(trans_out, t),self.injection(h, e, trans_out), and thereturn h_outinRecurrentBlock.forwardon the relevant flags.Doesn't:
main.n_loopsargument tomodel(...)per step). See Add experiments/ suite for inference-time loop scaling validation #27 for a referenceexperiments/train.pythat does this with--loop_sample_mode random_set --loop_choices.freeze_moe_routerin a way that changes the model; the flag is a config-level signal that training code can read to callmodel.recurrent.block.ffn.router.weight.requires_grad_(False)after construction. This keeps the model code pure.Test plan
python -c "from open_mythos import OpenMythos; from open_mythos.variants import mythos_1b; m = OpenMythos(mythos_1b())"— no regressions at default flags.requires_grad_(False)) forward and backward end-to-end in bf16 on H100 in the 13-run study in Empirical test of the depth-extrapolation claim: U-shape with fixed-loop training, flat plateau with random-loop training #28.disable_act=True+ stochastic-depth training produces the monotonic loop-scaling curve reported in Empirical test of the depth-extrapolation claim: U-shape with fixed-loop training, flat plateau with random-loop training #28.Related
--loop_sample_mode,--loop_choices) for exercising these flags at scale.Made with Cursor