
Attention mechanisms drive LLM success but create computational and memory bottlenecks that scale rapidly with sequence length. We observe substantial redundancy in attention: KV cache can be compressed significantly and attention maps across heads show high similarity.
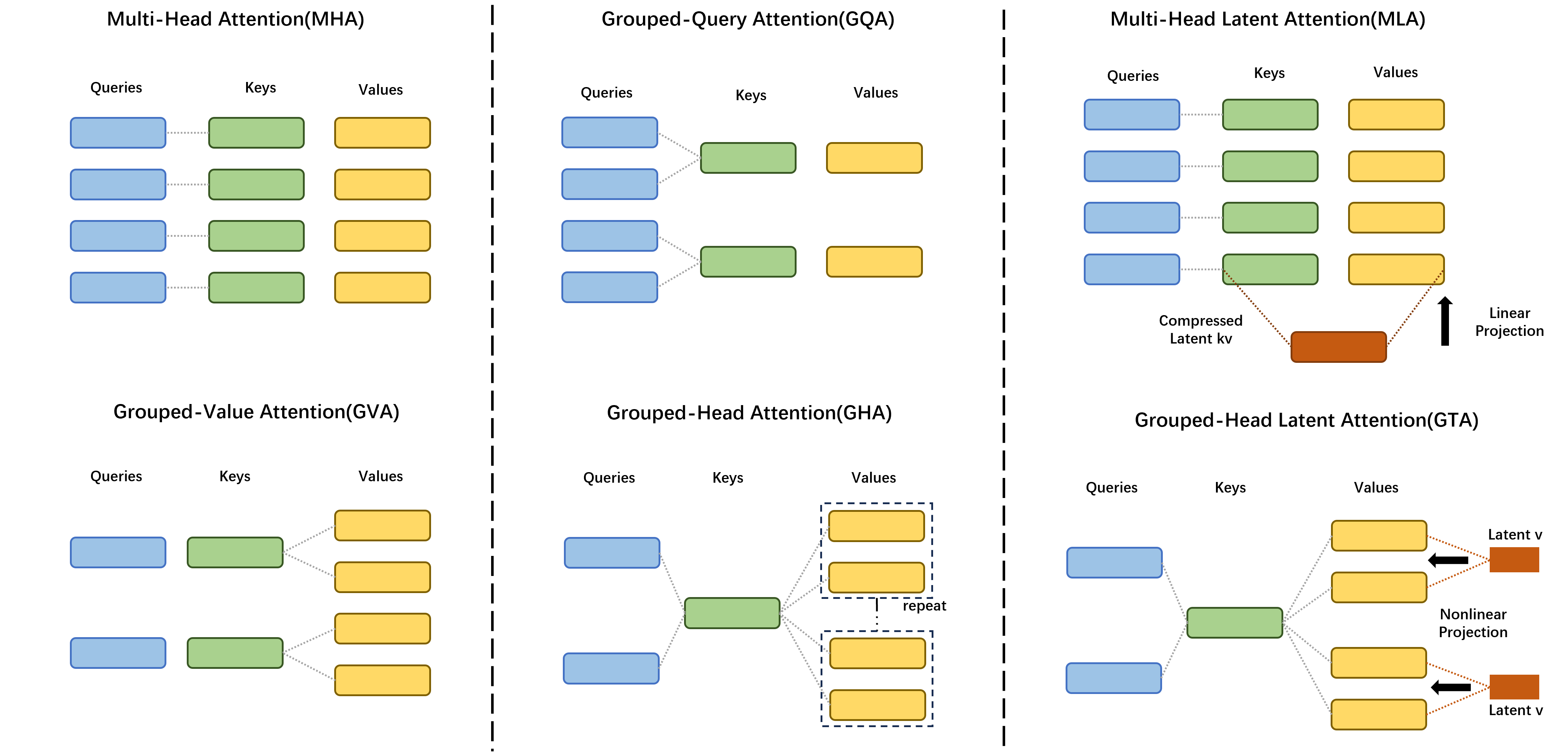
Traditional Multi-Head Attention (MHA) treats each attention head independently, causing computational redundancy. GTA groups attention heads into clusters (e.g., 4 heads per group) and shares a single attention matrix within each group. This eliminates redundant computations while preserving multi-head expressiveness.

GTA compresses all value vectors into a unified low-dimensional latent representation and employs a lightweight WaLU decoder for dynamic reconstruction. This approach generates customized value vectors on-demand for each attention group, achieving 70% memory reduction while preserving individual head expressiveness.
We trained full 1B parameter models (GTA-1B and GQA-1B) over 50,000 steps to validate GTA's scalability. All training logs and metrics are publicly available on Wandb to ensure experimental transparency and reproducibility. The loss curves below demonstrate that GTA maintains stable convergence with highly matched training trajectories despite using only 30% of GQA's KV cache size. This proves that our efficient attention mechanism doesn't compromise model optimization or final performance.

We evaluated both base and fine-tuned versions across comprehensive benchmarks, maintaining identical non-attention parameters for fair comparison. The results show that GTA-1B achieves comparable performance to GQA-1B while requiring significantly fewer resources. Notably, the fine-tuned GTA-1B model (GTA-1B-SFT) outperforms its GQA counterpart with an average improvement of 1.53% across all benchmarks.
| Model | PIQA | HellaS. | LogiQA | SIQA | ARC‑e | ARC‑c | BoolQ | MathQA | TQA | BBH | IFEval | MBPP | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GQA‑1B | 75.03 | 46.46 | 24.42 | 46.26 | 77.02 | 42.58 | 63.89 | 25.56 | 40.48 | 23.01 | 9.90 | 12.80 | 40.62 |
| GTA‑1B | 74.59 | 46.47 | 23.50 | 44.26 | 75.63 | 40.87 | 62.01 | 25.93 | 39.01 | 21.01 | 9.80 | 11.60 | 39.56 |
| GQA‑1B‑SFT | 74.31 | 45.52 | 20.58 | 42.42 | 70.45 | 36.09 | 63.57 | 26.26 | 40.89 | 22.01 | 29.76 | 15.80 | 40.64 |
| GTA‑1B‑SFT | 74.59 | 45.20 | 19.80 | 45.08 | 71.30 | 39.16 | 65.01 | 26.47 | 41.30 | 25.50 | 36.04 | 16.60 | 42.17 |
The table below compares computational complexity and memory requirements across different attention mechanisms. GTA achieves the optimal balance between efficiency and expressivity, with KV cache reduced to (n_k d_h + n_c d_l)N and attention computation to n_q(d_k+d_l)N², while maintaining strong expressivity.
| Attention Mechanism | KV Cache | Attention computation | Linear computation | Expressivity |
|---|---|---|---|---|
| MHA | Strong | |||
| GQA | Moderate | |||
| MLA | Strong | |||
| GVA | Moderate | |||
| GHA | Weak | |||
| GTA (Ours) | Strong |
We conducted comprehensive efficiency evaluations using LLM-Viewer on NVIDIA H100 GPUs. The analysis reveals that GTA-1B consistently outperforms GQA-1B in both compute-intensive prefill and I/O-intensive decode phases across various sequence lengths and batch sizes. The efficiency gains become more pronounced with longer sequences, demonstrating GTA's superior scalability.

To validate practical applicability, we tested GTA-1B across diverse hardware platforms (NVIDIA H100/A800, RTX 3060, Apple M2, BCM2712) using the transformers library. The benchmark results show consistent performance advantages across all hardware types, with GTA-1B demonstrating superior prefill and decode performance regardless of the underlying architecture. This hardware-agnostic efficiency makes GTA particularly suitable for both server-grade and consumer-level deployments.

In memory-constrained scenarios requiring GPU-CPU memory transfers, GTA-1B shows enhanced efficiency gains. The cache offloading benchmark demonstrates that GTA's reduced KV cache size significantly improves I/O-intensive operations, making it ideal for deployment in resource-limited environments.

To reproduce the training curve and performance, you can use the run_clm.py provided by HuggingFace. The exact training hyperparameter are as follows:
# content of run.sh
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS \
--nnodes $SLURM_NNODES \
--node_rank $SLURM_NODEID \
--rdzv_endpoint $ADDR:$PORT \
--rdzv_conf=join_timeout=36000000,read_timeout=3600000,timeout=36000000 \
"
eval_options=" \
--per_device_eval_batch_size $EVAL_BS \
--do_eval \
--evaluation_strategy steps \
--max_eval_samples $MAX_EVAL_SAMPLE \
--eval_steps $EVAL_STEP "
clm_options=" \
--train_file $DATA \
--trust_remote_code true \
--experiment_id $DATE \
--report_to wandb \
--block_size $BLOCK_SIZE \
--preprocessing_num_workers 64 \
--dataloader_num_workers 10 \
--learning_rate $LR \
--logging_steps 1 \
--num_train_epochs $EPOCH \
--bf16 true \
--config_name $CONFIG \
--tokenizer_name $CONFIG \
--model_type $MODEL_TYPE \
--per_device_train_batch_size $MICRO_BATCH \
--gradient_accumulation_steps $BATCH_ACC \
--optim adamw_hf \
--lr_scheduler_type cosine \
--warmup_ratio $WARM_RATIO \
--gradient_checkpointing true \
--save_strategy steps \
--save_steps $SAVE_STEP \
--deepspeed $DEEPSPEED \
--overwrite_output_dir \
--output_dir $SAVED_PRETRAIN_CHECKPOINT_PATH \
--cache_dir $CACHE \
--do_train \
SCRIPTS="run_clm_run.py"
run_cmd="torchrun $DISTRIBUTED_ARGS $SCRIPTS ${clm_options} ${eval_options}"
echo ${run_cmd}
eval ${run_cmd}We provide a comprehensive analysis framework based on LLM Viewer to evaluate the computational efficiency of different attention mechanisms. Our modified implementation is available in the llm_viewer/ directory.
To reproduce the efficiency analysis results:
cd llm_viewer
bash cal.sh- Scaled Training Data Models: Release GTA models trained on larger datasets via Hugging Face to demonstrate performance at scale
- Multi-Scale Model Family: Deploy GTA models across different parameter scales (3B, 7B, 13B, 30B+) on Hugging Face for comprehensive evaluation
- Efficient Inference Implementations: Develop optimized GTA implementations for llama.cpp and vLLM to enable high-performance deployment
We extend our deepest appreciation to our team members for their dedication and contributions from January 2025 to the present.
The code in this repository is released under the MIT License. Limitations: While we strive to address safety concerns and promote the generation of ethical and lawful text, the probabilistic nature of language models may still produce unforeseen outputs. These may include biased, discriminatory, or otherwise harmful content. Users are advised not to disseminate such material. We disclaim any liability for consequences resulting from the distribution of harmful information.
If you find Project GTA helpful for your research or applications, please cite as follows:
@misc{sun2025gtagroupedheadlatentattention,
title={GTA: Grouped-head latenT Attention},
author={Luoyang Sun and Jiwen Jiang and Cheng Deng and Xinjian Wu and Haifeng Zhang and Lei Chen and Lionel Ni and Jun Wang},
year={2025},
eprint={2506.17286},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.17286},
}