![]()
A lightweight diffusion library for training and sampling from diffusion and flow models. Features:
- Designed for ease of experimentation when training new models or developing new samplers
- Dataset support: 2D toy datasets, pixel and latent-space image datasets
- Example training code (with close to SOTA FID): FashionMNIST, CIFAR10, Imagenet
- Models: MLP, U-Net and DiT
- Supports multiple parameterizations: score-, flow- or data-prediction
- Small but extensible core: less than 100 lines of code for training and sampling
To install from pypi:
pip install smalldiffusion
For local development with uv:
uv sync --extra dev --extra test --extra examples
uv run pytest
To train and sample from the Swissroll toy dataset in 10 lines of code (see
examples/toyexample.ipynb for a detailed
guide):
from torch.utils.data import DataLoader
from smalldiffusion import Swissroll, TimeInputMLP, ScheduleLogLinear, training_loop, samples
dataset = Swissroll(np.pi/2, 5*np.pi, 100)
loader = DataLoader(dataset, batch_size=2048)
model = TimeInputMLP(hidden_dims=(16,128,128,128,128,16))
schedule = ScheduleLogLinear(N=200, sigma_min=0.005, sigma_max=10)
trainer = training_loop(loader, model, schedule, epochs=15000)
losses = [ns.loss.item() for ns in trainer]
*xt, x0 = samples(model, schedule.sample_sigmas(20), gam=2)Results on various toy datasets:

We can also train conditional diffusion models and sample from them using classifier-free guidance. In examples/cond_tree_model.ipynb, samples from each class in the 2D tree dataset are represented with a different color.
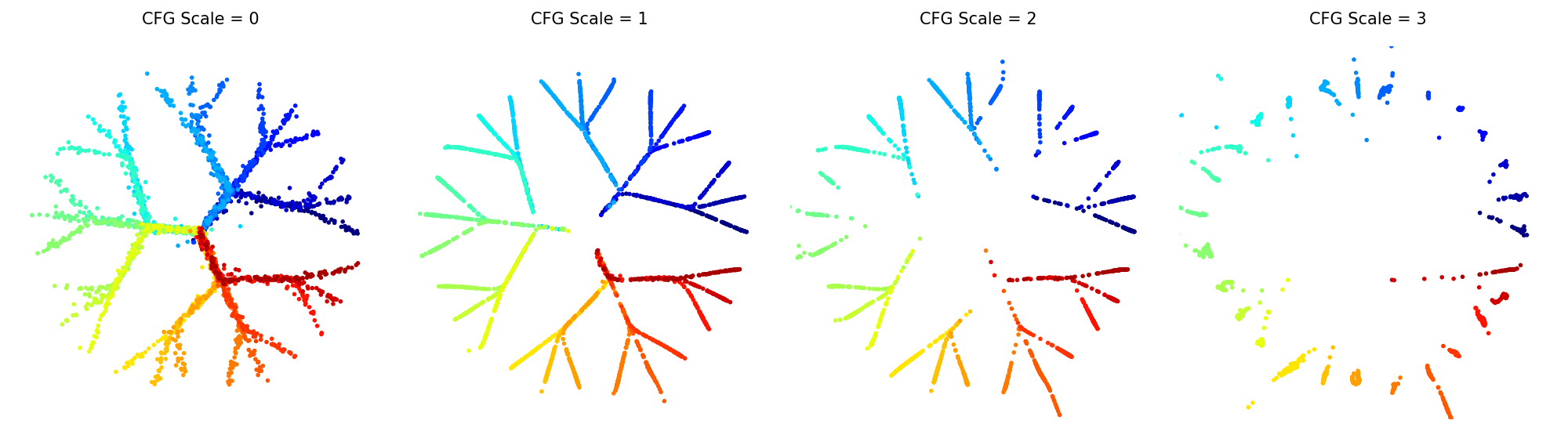
We provide a concise implementation of the diffusion transformer introduced in [Peebles and Xie 2022].
We provide an example script for training a DiT-B/2
model on ImageNet 256×256 using the flow matching formulation in the latent
space of Stable Diffusion's
VAE. The script trains on
precomputed VAE latents and supports multi-GPU training via accelerate:
uv run accelerate config
uv run accelerate launch examples/imagenet_dit.py
After training for 400k steps (~10 hours on 8 GPUs), the model achieves an unconditional FID of around 27, compared to 33 for SiT and 43 for DiT.

To train a diffusion transformer model on the FashionMNIST dataset and
generate a batch of samples (after first running uv run accelerate config):
uv run accelerate launch examples/fashion_mnist_dit.py
With the provided default parameters and training on a single GPU for around 2 hours, the model can achieve a FID score of around 5-6, producing the following generated outputs:

The same code can be used to train U-Net-based models.
uv run accelerate launch examples/fashion_mnist_unet.py
We also provide example code to train a U-Net on the CIFAR-10 dataset, with an unconditional FID of around 3-4:
uv run accelerate launch examples/cifar_unet.py

smalldiffusion's sampler works with any pretrained diffusion model, and supports
DDPM, DDIM as well as accelerated sampling algorithms. In
examples/diffusers_wrapper.py, we provide a
simple wrapper for any pretrained huggingface
diffusers latent diffusion model,
enabling sampling from pretrained models with only a few lines of code:
from diffusers_wrapper import ModelLatentDiffusion
from smalldiffusion import ScheduleLDM, samples
schedule = ScheduleLDM(1000)
model = ModelLatentDiffusion('stabilityai/stable-diffusion-2-1-base')
model.set_text_condition('An astronaut riding a horse')
*xts, x0 = samples(model, schedule.sample_sigmas(50))
decoded = model.decode_latents(x0)It is easy to experiment with different sampler parameters and sampling
schedules, as demonstrated in examples/stablediffusion.py. A
few examples on tweaking the parameter gam:

The core of smalldiffusion depends on the interaction between data, model
and schedule objects. Here we give a specification of these objects. For a
detailed introduction to diffusion models and the notation used in the code, see
the accompanying tutorial.
The library targets Python 3.10+ (see requires-python in
pyproject.toml). After a local checkout, install everything
needed for tests and examples with uv sync --all-extras (or
make install-local), or install subsets with
uv sync --extra dev --extra test --extra examples.
For training diffusion models, smalldiffusion uses PyTorch
Dataset
and DataLoader
batches.
By default, training_loop expects each batch to be a tensor of data only. To
drop labels (or otherwise map items), wrap the underlying dataset with
MappedDataset(dataset, fn) so each __getitem__ returns what the loop should
see.
For classifier-free guidance–style conditional training, pass
conditional=True to training_loop. Each batch should then be a pair
(x0, cond) (e.g. images and integer class ids); see
generate_train_sample for how batches are
split.
Three 2D toy datasets are provided: Swissroll,
DatasaurusDozen,
and TreeDataset.
All model objects should subclass torch.nn.Module and integrate with the
training and sampling hooks used in diffusion.py.
They should define:
input_dims: a tuple of spatial/channel dimensions for one sample (no batch dimension).rand_input(batchsize): i.i.d. standard normal noise with shape[batchsize, *input_dims]. You can inherit this fromModelMixinonceinput_dimsis set.
The model forward is called as forward(x, sigma, cond=None) where:
xhas shape[B, *input_dims].sigmais either a scalar (shape == ()), broadcast to the whole batch, or per-sample with shape[B, 1, …, 1]matchingx.condis optional conditioning (e.g. class indices for CFG).
By default, ModelMixin trains the network to
predict additive noise eps and implements get_loss accordingly. For other
targets, compose the model class with PredX0, PredV, or PredFlow
(score / v-prediction / flow-style objectives); those wrappers adjust the loss
and implement predict_eps so the shared samples() loop still applies.
Sampling calls predict_eps (and predict_eps_cfg when cfg_scale > 0).
A Schedule holds a 1D tensor of sigma values (noise level or, for flow
schedules, continuous time). Subclasses build that tensor; you can also
instantiate Schedule(sigmas) directly. Methods:
sample_sigmas(steps): decreasing sequence for sampling (lengthsteps + 1, trailing spacing as in Table 2 of https://arxiv.org/abs/2305.08891).sample_batch(x0): randomsigmafor each row of batchx0, with shape broadcastable tox0(uses batch size and device fromx0).
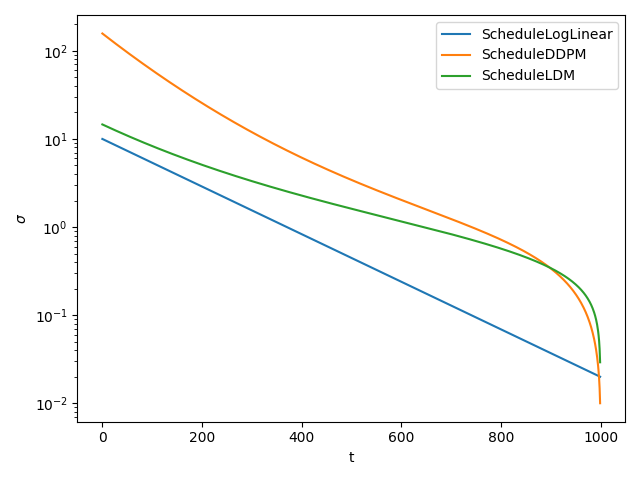
Built-in schedules:
ScheduleLogLinear: simple log-spaced sigmas; strong default for toy and small modelsScheduleDDPM: standard pixel-space diffusionScheduleLDM: latent diffusion (Stable Diffusion–style)ScheduleSigmoid: GeoDiffScheduleCosine: iDDPMScheduleFlow: flow matching with uniform time in[t_min, t_max]ScheduleLogNormalFlow: extendsScheduleFlowwith logit-normal times for faster training
The figure below compares several of these with default parameters (diffusion sigmas as a function of step index).
training_loop is a generator that runs
epochs passes over loader, using get_loss from the model’s class (so
PredX0 / PredV / PredFlow work without changing the loop). It accepts
optional accelerator (Hugging Face Accelerate)
and conditional as above. Each step yields a namespace of locals (e.g. loss,
optimizer, x0, sigma).
for ns in training_loop(loader, model, schedule):
print(ns.loss.item())
Pass a prepared Accelerator instance to use distributed or mixed-precision
training; the examples use accelerate launch for multi-GPU runs.
samples is a generator that takes model, a
decreasing list/tensor of sigmas (typically schedule.sample_sigmas(steps)),
and sampler hyperparameters gam and mu. Optional arguments include
batchsize, initial latent xt, conditioning cond, cfg_scale for
classifier-free guidance, and accelerator. It yields successive xt states.
Common choices:
- DDPM [Ho et al.]:
gam=1,mu=0.5. - DDIM [Song et al.]:
gam=1,mu=0. - Accelerated sampling [Permenter and Yuan]:
gam=2(withmu=0).
For more detail on unifying these samplers, see Appendix A of [Permenter and Yuan].